

阅读(1089)
赞(7)
AI人工智能 可视化音频信号 - 从文件读取并进行处理
2020-09-24 10:04:49 更新
这是构建语音识别系统的第一步,因为它可以帮助您理解音频信号的结构。 处理音频信号可遵循的一些常见步骤如下所示 -
记录 当必须从文件中读取音频信号时,首先使用麦克风录制。
采样 用麦克风录音时,信号以数字形式存储。 但为了解决这个问题,机器需要使用离散数字形式。 因此,我们应该以某个频率进行采样,并将信号转换为离散数字形式。 选择高频采样意味着当人类听到信号时,他们会感觉它是一个连续的音频信号。
示例
以下示例显示了使用 Python 存储在文件中的逐步分析音频信号的方法。 这个音频信号的频率是 44,100HZ。
下面导入必要的软件包 -
import numpy as np
import matplotlib.pyplot as plt
from scipy.io import wavfile现在,读取存储的音频文件。 它会返回两个值:采样频率和音频信号。 提供存储音频文件的路径,如下所示 -
frequency_sampling, audio_signal = wavfile.read("/Users/admin/audio_file.wav")使用显示的命令显示音频信号的采样频率,信号的数据类型及其持续时间等参数 -
print('\nSignal shape:', audio_signal.shape)
print('Signal Datatype:', audio_signal.dtype)
print('Signal duration:', round(audio_signal.shape[0] /
float(frequency_sampling), 2), 'seconds')这一步涉及如下所示对信号进行标准化 -
audio_signal = audio_signal / np.power(2, 15)在这一步中,从这个信号中提取出前 100 个值进行可视化。 为此目的使用以下命令 -
audio_signal = audio_signal [:100]
time_axis = 1000 * np.arange(0, len(signal), 1) / float(frequency_sampling)现在,使用下面给出的命令可视化信号 -
plt.plot(time_axis, signal, color='blue')
plt.xlabel('Time (milliseconds)')
plt.ylabel('Amplitude')
plt.title('Input audio signal')
plt.show()下面输出图形是上述音频信号提取的数据,如图所示 -
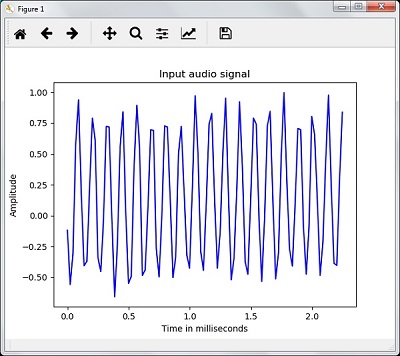
Signal shape: (132300,)
Signal Datatype: int16
Signal duration: 3.0 seconds