阅读(3703)
赞(6)
AI人工智能 随机森林分类器
2020-09-23 15:03:01 更新
集成方法是将机器学习模型组合成更强大的机器学习模型的方法。 随机森林是决策树的集合,就是其中之一。 它比单一决策树好,因为在保留预测能力的同时,通过平均结果可以减少过度拟合。 在这里,我们将在 scikit 学习癌症数据集上实施随机森林模型。
导入必要的软件包 -
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_breast_cancer
cancer = load_breast_cancer()
import matplotlib.pyplot as plt
import numpy as np现在,需要按照以下方式提供数据集
cancer = load_breast_cancer()
X_train, X_test, y_train,
y_test = train_test_split(cancer.data, cancer.target, random_state = 0)在提供数据集之后,需要拟合可以如下完成的模型 -
forest = RandomForestClassifier(n_estimators = 50, random_state = 0)
forest.fit(X_train,y_train)现在,获得训练以及测试子集的准确性:如果增加估计器的数量,那么测试子集的准确性也会增加。
print('Accuracy on the training subset:(:.3f)',format(forest.score(X_train,y_train)))
print('Accuracy on the training subset:(:.3f)',format(forest.score(X_test,y_test)))上面代码,输出结果如下所示 -
Accuracy on the training subset:(:.3f) 1.0
Accuracy on the training subset:(:.3f) 0.965034965034965
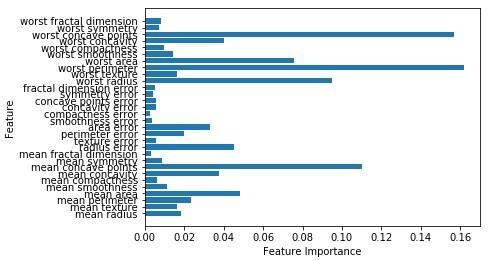
现在,与决策树一样,随机森林具有 feature_importance 模块,它将提供比决策树更好的特征权重视图。 它可以如下绘制和可视化 -
n_features = cancer.data.shape[1]
plt.barh(range(n_features),forest.feature_importances_, align='center')
plt.yticks(np.arange(n_features),cancer.feature_names)
plt.xlabel('Feature Importance')
plt.ylabel('Feature')
plt.show()执行上面代码,得到以下输出结果 -