

AI人工智能 最常见的机器学习算法
在本节中,我们将学习最常见的机器学习算法。 算法如下所述 -
线性回归 它是统计和机器学习中最著名的算法之一。
基本概念 - 主要是线性回归是一个线性模型,假设输入变量 x 和单个输出变量 y 之间的线性关系。 换句话说,y可以由输入变量 x 的线性组合来计算。 变量之间的关系可以通过拟合最佳线来确定。
线性回归的类型
线性回归有以下两种类型 -
- 简单线性回归 - 如果线性回归算法只有一个独立变量,则称为简单线性回归。
- 多元线性回归 - 如果线性回归算法具有多个独立变量,则称其为多元线性回归。
线性回归主要用于基于连续变量估计实际值。 例如,可以通过线性回归来估计一天内基于实际价值的商店总销售额。
Logistic 回归 它是一种分类算法,也称为 logit 回归。
主要逻辑回归是一种分类算法,用于根据给定的一组自变量来估计离散值,如 0 或 1,真或假,是或否。 基本上,它预测的概率因此它的输出在 0和 1 之间。
决策树 决策树是一种监督学习算法,主要用于分类问题。
基本上它是一个基于自变量表示为递归分区的分类器。 决策树具有形成根树的节点。 有根树是一个带有称为“根”节点的定向树。 Root 没有任何传入边缘,所有其他节点都有一个传入边缘。 这些节点被称为树叶或决策节点。 例如,考虑下面的决策树来判断一个人是否适合。
支持向量机(SVM)
它用于分类和回归问题。 但主要用于分类问题。 SVM 的主要概念是将每个数据项绘制为n维空间中的一个点,每个特征的值是特定坐标的值。 这里 n 将是功能。 以下是了解 SVM 概念的简单图形表示 -
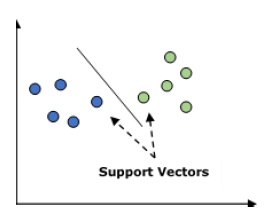
在上图中,有两个特征,因此首先需要在二维空间中绘制这两个变量,其中每个点都有两个坐标,称为支持向量。 该行将数据分成两个不同的分类组。 这条线将是分类器。
朴素贝叶斯 这也是一种分类技术。 这种分类技术背后的逻辑是使用贝叶斯定理来构建分类器。 假设是预测变量是独立的。 简而言之,它假设类中某个特征的存在与任何其他特征的存在无关。 以下是贝叶斯定理的等式 -
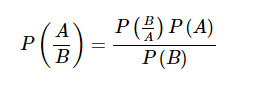
朴素贝叶斯模型易于构建,特别适用于大型数据集。
K-最近邻居 (KNN)
它用于问题的分类和回归。 它被广泛用于解决分类问题。 该算法的主要概念是它用来存储所有可用的案例,并通过其k个邻居的多数选票来分类新案例。 然后将该情况分配给通过距离函数测量的K近邻中最常见的类。 距离函数可以是欧几里得,明可夫斯基和海明距离。 考虑以下使用 KNN -
- 计算上 KNN 比用于分类问题的其他算法昂贵。
- 变量的规范化需要其他更高的范围变量可以偏差。
- 在 KNN 中,需要在噪音消除等预处理阶段进行工作。
K 均值聚类
顾名思义,它用于解决聚类问题。 它基本上是一种无监督学习。 K-Means 聚类算法的主要逻辑是通过许多聚类对数据集进行分类。 按照这些步骤通过 K-means 形成聚类 -
- K-means 为每个簇选取 k 个点,称为质心。
- 每个数据点形成具有最接近质心的群集,即k个群集。
- 它将根据现有集群成员查找每个集群的质心。
- 需要重复这些步骤直到收敛。
随机森林 它是一个监督分类算法。 随机森林算法的优点是它可以用于分类和回归两类问题。 基本上它是决策树的集合(即森林),或者可以说决策树的集合。随机森林的基本概念是每棵树给出一个分类,并且森林从它们中选择最好的分类。以下是随机森林算法的优点 -
- 随机森林分类器可用于分类和回归任务。
- 可以处理缺失的值。
- 即使在森林中有更多的树,它也不会过度适合模型。