AI人工智能 在Python中构建分类器
在本节中,我们将学习如何在 Python 中构建分类器。
朴素贝叶斯分类器
朴素贝叶斯是一种使用贝叶斯定理建立分类器的分类技术。 假设是预测变量是独立的。 简而言之,它假设类中某个特征的存在与任何其他特征的存在无关。要构建朴素贝叶斯分类器,我们需要使用名为 scikit learn 的 python库。 在 scikit 学习包中,有三种类型的朴素贝叶斯模型被称为 Gaussian,Multinomial 和 Bernoulli。
要构建朴素贝叶斯机器学习分类器模型,需要以下“减号”
数据集
我们将使用名为 Breast Cancer Wisconsin Diagnostic Database数据集_blank。 数据集包括有关乳腺癌肿瘤的各种信息,以及恶性或良性分类标签。 该数据集在 569 个肿瘤上具有 569 个实例或数据,并且包括关于 30 个属性或特征(诸如肿瘤的半径,纹理,光滑度和面积)的信息。可以从 sklearn 包中导入这个数据集。
朴素贝叶斯模型
为了构建朴素贝叶斯分类器,需要一个朴素贝叶斯模型。 如前所述,scikit 学习包中有三种类型的 NaïveBayes 模型,分别称为 Gaussian,Multinomial 和 Bernoulli。 在下面的例子中,将使用高斯朴素贝叶斯模型。
通过使用上述内容,我们将建立一个朴素贝叶斯机器学习模型来使用肿瘤信息来预测肿瘤是否是恶性的或良性的。
首先,我们需要安装 sklearn 模块。 它可以通过以下命令完成 -
import sklearn现在,需要导入名为 Breast Cancer Wisconsin Diagnostic Database 的数据集。
from sklearn.datasets import load_breast_cancer现在,以下命令将加载数据集。
data = load_breast_cancer()数据可以按如下方式组织 -
label_names = data['target_names']
labels = data['target']
feature_names = data['feature_names']
features = data['data']现在,为了使它更清晰,可以在以下命令的帮助下打印类标签,第一个数据实例的标签,功能名称和功能的值 -
print(label_names)上述命令将分别打印恶性和良性的类名。 它显示为下面的输出 -
['malignant' 'benign']
现在,下面给出的命令将显示它们映射到二进制值 0 和 1。这里 0 表示恶性肿瘤,1 表示良性癌症。 它显示为下面的输出 -
print(labels[0])
0以下两个命令将生成功能名称和功能值。
print(feature_names[0])
mean radius
print(features[0])
[ 1.79900000e+01 1.03800000e+01 1.22800000e+02 1.00100000e+03
1.18400000e-01 2.77600000e-01 3.00100000e-01 1.47100000e-01
2.41900000e-01 7.87100000e-02 1.09500000e+00 9.05300000e-01
8.58900000e+00 1.53400000e+02 6.39900000e-03 4.90400000e-02
5.37300000e-02 1.58700000e-02 3.00300000e-02 6.19300000e-03
2.53800000e+01 1.73300000e+01 1.84600000e+02 2.01900000e+03
1.62200000e-01 6.65600000e-01 7.11900000e-01 2.65400000e-01
4.60100000e-01 1.18900000e-01]
从以上输出可以看出,第一个数据实例是一个主要半径为 1.7990000e + 01 的恶性肿瘤。
要在未看到的数据上测试模型,我们需要将数据分解为训练和测试数据。 它可以在下面的代码的帮助下完成 -
from sklearn.model_selection import train_test_split
上述命令将从 sklearn 中导入 train_test_split 函数,下面的命令将数据分解为训练和测试数据。 在下面的例子中,使用 40%的数据进行测试,并将提示数据用于训练模型。
train, test, train_labels, test_labels =
train_test_split(features,labels,test_size = 0.40, random_state = 42)现在,使用以下命令构建模型 -
from sklearn.naive_bayes import GaussianNB
上述命令将从 sklearn 中导入train_test_split 函数,下面的命令将数据分解为训练和测试数据。 在下面的例子中,我们使用 40% 的数据进行测试,并将提示数据用于训练模型。
train, test, train_labels, test_labels =
train_test_split(features,labels,test_size = 0.40, random_state = 42)现在,使用以下命令构建模型 -
from sklearn.naive_bayes import GaussianNB上述命令将导入 GaussianNB 模块。 现在,使用下面给出的命令,需要初始化模型。
gnb = GaussianNB()
将通过使用 gnb.fit()将它拟合到数据来训练模型。
model = gnb.fit(train, train_labels)现在,通过对测试数据进行预测来评估模型,并且可以按如下方式完成 -
preds = gnb.predict(test)
print(preds)
[1 0 0 1 1 0 0 0 1 1 1 0 1 0 1 0 1 1 1 0 1 1 0 1 1 1 1 1 1
0 1 1 1 1 1 1 0 1 0 1 1 0 1 1 1 1 1 1 1 1 0 0 1 1 1 1 1 0
0 1 1 0 0 1 1 1 0 0 1 1 0 0 1 0 1 1 1 1 1 1 0 1 1 0 0 0 0
0 1 1 1 1 1 1 1 1 0 0 1 0 0 1 0 0 1 1 1 0 1 1 0 1 1 0 0 0
1 1 1 0 0 1 1 0 1 0 0 1 1 0 0 0 1 1 1 0 1 1 0 0 1 0 1 1 0
1 0 0 1 1 1 1 1 1 1 0 0 1 1 1 1 1 1 1 1 1 1 1 1 0 1 1 1 0
1 1 0 1 1 1 1 1 1 0 0 0 1 1 0 1 0 1 1 1 1 0 1 1 0 1 1 1 0
1 0 0 1 1 1 1 1 1 1 1 0 1 1 1 1 1 0 1 0 0 1 1 0 1]
上述0和1系列是肿瘤类别的预测值,即恶性和良性。
现在,通过比较两个数组即 test_labels 和 preds,可以看到模型的准确性。 我们将使用 accuracy_score() 函数来确定准确性。 考虑下面的命令 -
from sklearn.metrics import accuracy_score
print(accuracy_score(test_labels,preds))
0.951754385965结果显示 NaïveBayes 分类器准确率为 95.17%。
这是基于 NaïveBayse 高斯模型的机器学习分类器。
支持向量机(SVM) 基本上,支持向量机(SVM)是一种有监督的机器学习算法,可用于回归和分类。 SVM 的主要概念是将每个数据项绘制为n维空间中的一个点,每个特征的值是特定坐标的值。以下是了解 SVM 概念的简单图形表示 -
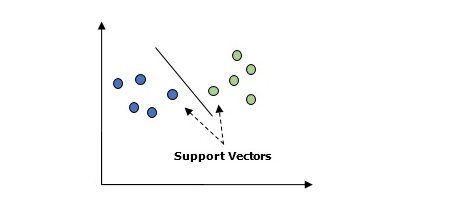
在上图中,有两个特征。 因此,首先需要在二维空间中绘制这两个变量,其中每个点都有两个坐标,称为支持向量。 该行将数据分成两个不同的分类组。 这条线将是分类器。
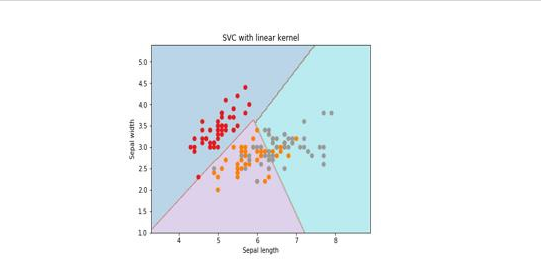
在这里,将使用 scikit-learn 和 iris 数据集来构建 SVM 分类器。 Scikitlearn 库具有 sklearn.svm 模块并提供 sklearn.svm.svc 进行分类。 下面显示了基于 4 个特征来预测虹膜植物种类的 SVM 分类器。
数据集
我们将使用包含3个类别(每个类别为 50 个实例)的虹膜数据集,其中每个类别指的是一类虹膜工厂。 每个实例具有四个特征,即萼片长度,萼片宽度,花瓣长度和花瓣宽度。 下面显示了基于4个特征来预测虹膜植物分类的 SVM 分类器。
内核 这是 SVM 使用的技术。 基本上这些功能采用低维输入空间并将其转换到更高维空间。 它将不可分离的问题转换成可分离的问题。 核函数可以是线性,多项式,rbf 和 sigmoid 中的任何一种。 在这个例子中,将使用线性内核。
现在导入下列软件包 -
import pandas as pd
import numpy as np
from sklearn import svm, datasets
import matplotlib.pyplot as plt现在,加载输入数据 -
iris = datasets.load_iris()我们使用前两个功能 -
X = iris.data[:, :2]
y = iris.target我们将用原始数据绘制支持向量机边界,创建一个网格来绘制。
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
h = (x_max / x_min)/100
xx, yy = np.meshgrid(np.arange(x_min, x_max, h),
np.arange(y_min, y_max, h))
X_plot = np.c_[xx.ravel(), yy.ravel()]需要给出正则化参数的值。
C = 1.0需要创建 SVM 分类器对象。参考以下代码 -
Svc_classifier = svm_classifier.SVC(kernel='linear',
C=C, decision_function_shape = 'ovr').fit(X, y)
Z = svc_classifier.predict(X_plot)
Z = Z.reshape(xx.shape)
plt.figure(figsize = (15, 5))
plt.subplot(121)
plt.contourf(xx, yy, Z, cmap = plt.cm.tab10, alpha = 0.3)
plt.scatter(X[:, 0], X[:, 1], c = y, cmap = plt.cm.Set1)
plt.xlabel('Sepal length')
plt.ylabel('Sepal width')
plt.xlim(xx.min(), xx.max())
plt.title('SVC with linear kernel')执行后得到以下结果 -