
很多小伙伴在学习编程的时候会出现相互之间互相借鉴代码参考的现象(借鉴学习是好事,但是代码抄袭是对别人劳动成果的否定)。但是有些时候代码拷贝过来一看确傻了眼,很多字符都出现了奇奇怪怪的乱码,有些则是一片一片的方块,这就是代码乱码,那么代码乱码怎么解决呢?且听小编细细分解。
出现乱码的原因——字符集
众所周知,计算机只认识0和1,不认识其他的字,但是我们最后要让计算机显示字,所以我们用一个字节(八位,有256种状态)来表示一个字符。对于英语国家而言,他们使用的字母只有26个,算上大写,加上数字,再加上一些标点符号和一些特殊处理,使用128位足够表示他们需要表示的所有内容了。于是他们设计出了ASCII码表,并且广为使用。
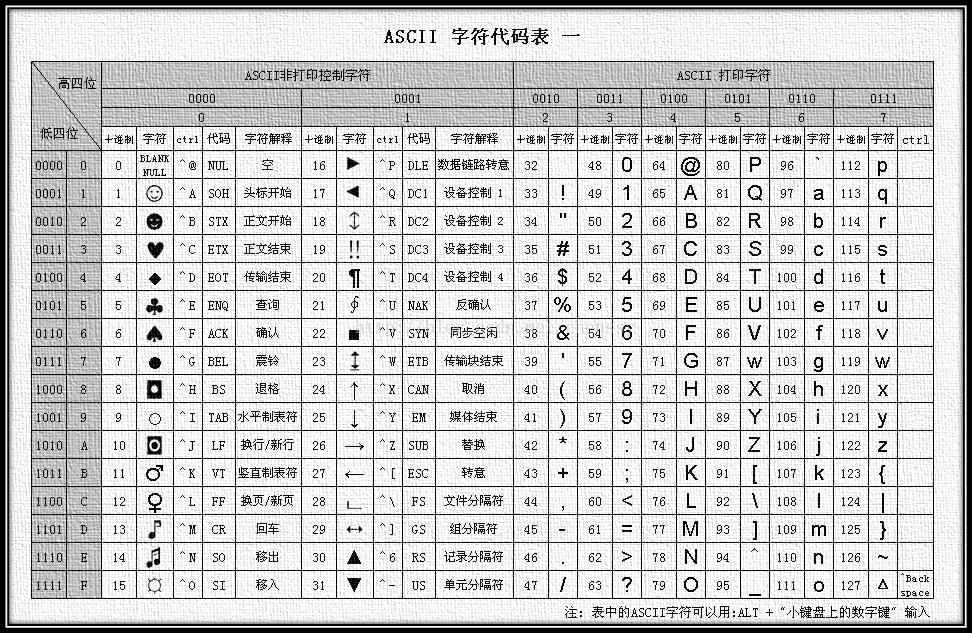
但是这个世界上并不是只有英文,还有中文,日文,韩文等文字,这些文字ASCII码表并没有对应的数值,所以很多文种都发展了专属的字符集。以中文为例子,我们发展出了gb2312以及gbk(gb2312的进阶版)两种字符集,它采用两个字节(一个字节没有办法表示所有汉字)而且兼容ASCII码。
再往后因为各个国家都有对应的字符集,会照成使用上的混乱,这时候Unicode出现了,它又被称为万国码,他可以表示所有语言的所有文字,其中最出名的是UTF-8,这是一种可变字节长度的编码,最长可以达到4字节。同样的,他也兼容ASCII码。
为什么会出现乱码——字符集选用错误
刚才介绍了三种字符集,其中有两种都有涉及到中文,也就是接下来我们的主角:utf-8和gbk(gb2312暂不做讨论)。
小编这里设定了两组对照试验以帮助各位读者了解乱码的原因:
使用utf-8编码的文件(乱码更多的是一些奇形怪状的文字):
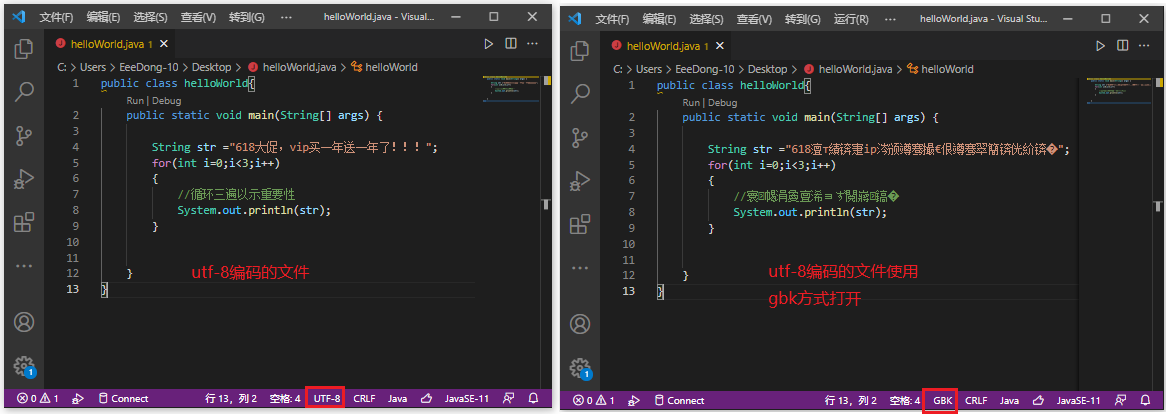
使用gbk编码的文件(乱码多为方片中带有一个问号):
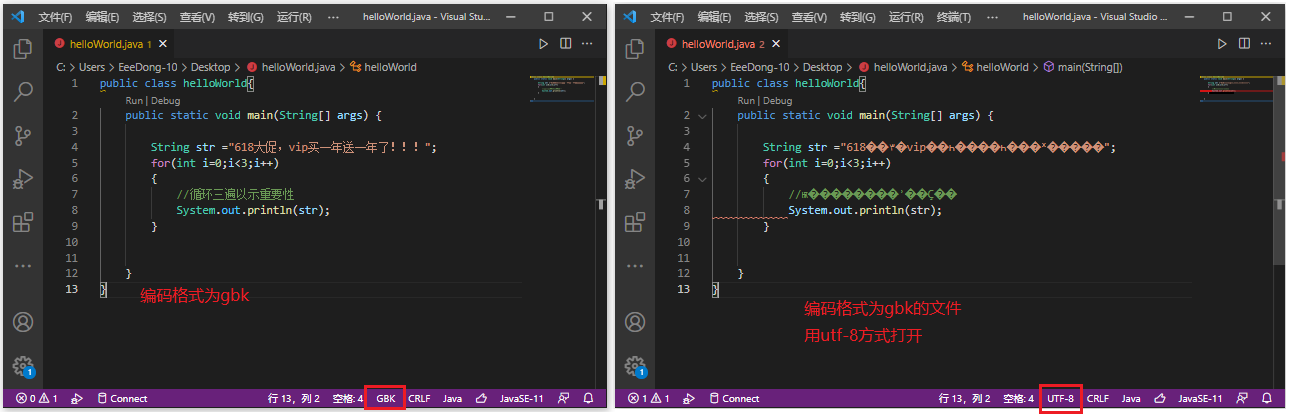
可以发现,这两种字符集如果选择错误的话,使用对方的字符集读取文件都会导致乱码。上述结果也给我们带来了乱码的一种简单的判断方式——根据乱码的情况判断应该使用什么字符集。
解决方法
出现乱码不要慌,只需要选择使用对应的正确方法重新打开就可以了。这里切记,千万不要点保存。因为因为点完保存后编辑器会把乱码以对应的格式保存,这样子这些乱码就只能是乱码,无法恢复了。
小编建议
其实从上面的结果还能得出一个结论:不管怎么乱码,ASCII码不会乱,之前字符集的介绍中也有提起。所以,如果注释使用英文,就不会出现乱码。就算必须使用中文,也可以在文件开头用英文注明该代码使用的字符集,方便后来者的阅读(这点python就做得比java好,默认使用utf-8)。
小结
以上就是关于代码乱码怎么解决的方法,更多编程小问题的解决,关注W3C技术头条,小编帮你解决!

