
基于无监督预训练语义索引召回:SimCSE、Diffcse
语义索引(可通俗理解为向量索引)技术是搜索引擎、推荐系统、广告系统在召回阶段的核心技术之一。语义索引模型的目标是:给定输入文本,模型可以从海量候选召回库中快速、准确地召回一批语义相关文本。语义索引模型的效果直接决定了语义相关的物料能否被成功召回进入系统参与上层排序,从基础层面影响整个系统的效果。
在召回阶段,最常见的方式是通过双塔模型,学习Document(简写为Doc)的向量表示,对Doc端建立索引,用ANN召回。我们在这种方式的基础上,引入无监督预训练策略,以如下训练数据为例:
代码语言:txt复制我手机丢了,我想换个手机 我想买个新手机,求推荐
学日语软件手机上的 手机学日语的软件
侠盗飞车罪恶都市怎样改车 侠盗飞车罪恶都市怎么改车SimCSE Diffcse 模型适合缺乏监督数据,但是又有大量无监督数据的匹配和检索场景。
1.基于无监督预训练语义索引召回前置工作
1.1技术方案
双塔模型,采用ERNIE1.0热启,在召回阶段引入 SimCSE 策略。
1.2 评估指标
(1)采用 Recall@1,Recall@5 ,Recall@10 ,Recall@20 和 Recall@50 指标来评估语义索引模型的召回效果。
效果评估
策略 | 模型 | Recall@1 | Recall@5 | Recall@10 | Recall@20 | Recall@50 |
|---|---|---|---|---|---|---|
SimCSE | ernie 1.0 | 42.374 | 57.505 | 62.641 | 67.09 | 72.331 |
SimCSE | rocketqa-zh-base-query-encoder | 50.108 | 64.005 | 68.288 | 72.306 | 77.306 |
1.3 环境依赖和安装说明
环境依赖
- python >= 3.6
- paddlepaddle >= 2.1.3
- paddlenlp >= 2.2
- hnswlib >= 0.5.2
- visualdl >= 2.2.2
- Hnswlib是一种用于高效近似最近邻搜索(ANN)的C 库,具有可扩展性,适用于多个领域。它基于分层和嵌套分区的概念,在建立索引时通过降低计算复杂度提高查询速度,并且还支持并行查询。
- Hnswlib使用一种名为“反演搜索”的技术来搜索最近的邻居,并利用固定大小的倒排列表存储每个向量的相似向量。它还具有可调整参数,可以根据需要来优化精度和速度之间的平衡,例如一次查询返回的最大邻居数、检索阈值等。
- 由于Hnswlib不依赖于任何特定类型的特征或数据格式,因此它可以应用于各种任务,例如图像检索、自然语言处理等。
1.4 代码结构
以下是本项目主要代码结构及说明:
代码语言:txt复制simcse/
├── model.py # SimCSE 模型组网代码
|—— deploy
|—— python
|—— predict.py # PaddleInference
├── deploy.sh # Paddle Inference的bash脚本
|—— scripts
├── export_model.sh # 动态图转静态图bash脚本
├── predict.sh # 预测的bash脚本
├── evaluate.sh # 召回评估bash脚本
├── run_build_index.sh # 索引的构建脚本
├── train.sh # 训练的bash脚本
|—— ann_util.py # Ann 建索引库相关函数
├── data.py # 无监督语义匹配训练数据、测试数据的读取逻辑
├── export_model.py # 动态图转静态图
├── predict.py # 基于训练好的无监督语义匹配模型计算文本 Pair 相似度
├── evaluate.py # 根据召回结果和评估集计算评估指标
|—— inference.py # 动态图抽取向量
|—— recall.py # 基于训练好的语义索引模型,从召回库中召回给定文本的相似文本
└── train.py # SimCSE 模型训练、评估逻辑1.5 数据准备
1.5.1数据集说明
我们基于开源的语义匹配数据集构造生成了面向语义索引的训练集、评估集、召回库。
样例数据如下:
代码语言:txt复制睡眠障碍与常见神经系统疾病的关系睡眠觉醒障碍,神经系统疾病,睡眠,快速眼运动,细胞增殖,阿尔茨海默病
城市道路交通流中观仿真研究
城市道路交通流中观仿真研究智能运输系统;城市交通管理;计算机仿真;城市道路;交通流;路径选择
网络健康可信性研究
网络健康可信性研究网络健康信息;可信性;评估模式
脑瘫患儿家庭复原力的影响因素及干预模式雏形 研究
脑瘫患儿家庭复原力的影响因素及干预模式雏形研究脑瘫患儿;家庭功能;干预模式
地西他滨与HA方案治疗骨髓增生异常综合征转化的急性髓系白血病患者近期疗效比较
地西他滨与HA方案治疗骨髓增生异常综合征转化的急性髓系白血病患者近期疗效比较
个案工作 社会化
个案社会工作介入社区矫正再社会化研究——以东莞市清溪镇为例社会工作者;社区矫正人员;再社会化;角色定位
圆周运动加速度角速度
圆周运动向心加速度物理意义的理论分析匀速圆周运动,向心加速度,物理意义,角速度,物理量,线速度,周期召回集,验证集,测试集与inbatch-negative实验的数据保持一致
1.5.2 数据集下载
数据已经加载/home/aistudio/literature_search_data下了
代码语言:txt复制├── milvus # milvus建库数据集
├── milvus_data.csv. # 构建召回库的数据
├── recall # 召回(语义索引)数据集
├── corpus.csv # 用于测试的召回库
├── dev.csv # 召回验证集
├── test.csv # 召回测试集
├── train.csv # 召回训练集
├── train_unsupervised.csv # 无监督训练集
├── sort # 排序数据集
├── test_pairwise.csv # 排序测试集
├── dev_pairwise.csv # 排序验证集
└── train_pairwise.csv # 排序训练集!unzip -d /home/aistudio/literature_search_data /home/aistudio/data/data225060/literature_search_data.zip#数据查看
import csv
def show_data(filename, num_rows=10):
with open(filename, 'r') as f:
reader = csv.reader(f)
header = next(reader) # 获取表头
print(header) # 打印表头
for i, row in enumerate(reader):
if i < num_rows: # 打印前num_rows行数据
print(row)
else:
break
line = '-' * 100
print(line)
# show_data('/home/aistudio/literature_search_data/milvus/milvus_data.csv', num_rows=5)
show_data('/home/aistudio/literature_search_data/recall/train_unsupervised.csv', num_rows=5)
show_data('/home/aistudio/literature_search_data/recall/train.csv', num_rows=5)
show_data('/home/aistudio/literature_search_data/recall/dev.csv', num_rows=5)
# show_data('/home/aistudio/literature_search_data/recall/corpus.csv', num_rows=5)
# show_data('/home/aistudio/literature_search_data/recall/test.csv', num_rows=5)
# show_data('/home/aistudio/LCQMC/train.txt', num_rows=5)
# show_data('/home/aistudio/LCQMC/LCQMC.valid.data', num_rows=5)['煤矸石-污泥基活性炭介导强化污水厌氧消化']['煤矸石-污泥基活性炭介导强化污水厌氧消化煤矸石', '污泥', '复合基活性炭', '厌氧消化', '直接种间电子传递']['. 睡眠障碍与常见神经系统疾病的关系']['睡眠障碍与常见神经系统疾病的关系睡眠觉醒障碍', '神经系统疾病', '睡眠', '快速眼运动', '细胞增殖', '阿尔茨海默病']['城市道路交通流中观仿真研究']['城市道路交通流中观仿真研究智能运输系统;城市交通管理;计算机仿真;城市道路;交通流;路径选择']----------------------------------------------------------------------------------------------------['从《唐律疏义》看唐代封爵贵族的法律特权t从《唐律疏义》看唐代封爵贵族的法律特权《唐律疏义》', '封爵贵族', '法律特权']['宁夏社区图书馆服务体系布局现状分析t宁夏社区图书馆服务体系布局现状分析社区图书馆', '社区图书馆服务', '社区图书馆服务体系']['人口老龄化对京津冀经济t京津冀人口老龄化对区域经济增长的影响京津冀', '人口老龄化', '区域经济增长', '固定效应模型']['英语广告中的模糊语t模糊语在英语广告中的应用及其功能模糊语', '英语广告', '表现形式', '语用功能']['甘氨酸二肽的合成t甘氨酸二肽合成中缩合剂的选择甘氨酸', '缩合剂', '二肽']['玉米农田生态系统水碳通量日变化特征研究t玉米农田生态系统水碳通量日变化特征研究玉米农田', '水汽通量', 'CO2通量', '冠层导度', '日变化']----------------------------------------------------------------------------------------------------['热处理对尼龙6 及其与聚酰胺嵌段共聚物共混体系晶体熔融行为和结晶结构的影响t热处理对尼龙6及其与聚酰胺嵌段共聚物共混体系晶体熔融行为和结晶结构的影响尼龙6', '聚酰胺嵌段共聚物', '芳香聚酰胺', '热处理']['面向生态系统服务的生态系统分类方案研发与应用.t面向生态系统服务的生态系统分类方案研发与应用']['huntington舞蹈病的动物模型tHuntington舞蹈病的动物模型']['试论我国海岸带经济开发的问题与前景t试论我国海岸带经济开发的问题与前景海岸带', '经济开发', '问题', '前景']['外语阅读焦虑与英语成绩及性别的关系t外语阅读焦虑与英语成绩及性别的关系外语阅读焦虑', '外语课堂焦虑', '英语成绩', '性别']['加油站风险分级管控t加油站工作危害风险分级研究加油站', '工作危害分析(JHA)', '风险分级管控']----------------------------------------------------------------------------------------------------['开初婚未育证明怎么弄?t初婚未育情况证明怎么开?t1']['谁知道她是网络美女吗?t爱情这杯酒谁喝都会醉是什么歌t0']['人和畜生的区别是什么?t人与畜生的区别是什么!t1']['男孩喝女孩的尿的故事t怎样才知道是生男孩还是女孩t0']['这种图片是用什么软件制作的?t这种图片制作是用什么软件呢?t1']['这腰带是什么牌子t护腰带什么牌子好t0']----------------------------------------------------------------------------------------------------!pip install -r requirements.txt#查看cuda
!nvcc --versionnvcc: NVIDIA (R) Cuda compiler driverCopyright (c) 2005-2021 NVIDIA CorporationBuilt on Sun_Feb_14_21:12:58_PST_2021Cuda compilation tools, release 11.2, V11.2.152Build cuda_11.2.r11.2/compiler.29618528_02. SimCSE(2021.04)模型训练评估预测
SimCSE是有大神陈丹琦发表的《Simple Contrastive Learning of Sentence Embeddings》,简单高效

SimCSE包含无监督(图左部分)和有监督(图右部分)两种方法。实线箭头代表正例,虚线代表负例。
- Unsupervised
创新点在于使用Dropout对文本增加噪音。
1.正例构造:利用Bert的随机Dropout,同一文本经过两次Bert enconder得到不同的句向量构成相似文本。
2.负例构造:同一个Batch中的其他样本作为负例被随机采样。
- Supervised
1.正例:标注数据
2.负例:同Batch内的其他样本
语义索引预训练模型下载链接:
以下模型结构参数为: TrasformerLayer:12, Hidden:768, Heads:12, OutputEmbSize: 256
Model | 训练参数配置 | 硬件 | MD5 |
|---|---|---|---|
SimCSE | <div style="width: 150pt">ernie 1.0 epoch:3 lr:5E-5 bs:64 max_len:64 </div> | <div style="width: 100pt">4卡 v100-16g</div> | 7c46d9b15a214292e3897c0eb70d0c9f |
2.1训练环境说明
- NVIDIA Driver Version: 440.64.00
- Ubuntu 16.04.6 LTS (Docker)
- Intel(R) Xeon(R) Gold 6148 CPU @ 2.40GHz
2.2 单机单卡训练/单机多卡训练
这里采用单机多卡方式进行训练,通过如下命令,指定 GPU 0,1,2,3 卡, 基于SimCSE训练模型,无监督的数据量比较大,4卡的训练的时长在16个小时左右。如果采用单机单卡训练,只需要把--gpu参数设置成单卡的卡号即可。
训练的命令如下:
- 也可以使用bash脚本:
sh scripts/train.sh#数据太大仅运行1个epoch作为尝试
� /home/aistudio/simcse
!unset CUDA_VISIBLE_DEVICES
# python -u -m paddle.distributed.launch --gpus '0,1,2,3'
!python -u -m paddle.distributed.launch --gpus '0'
train.py
--device gpu
--save_dir ./checkpoint/
--batch_size 16
--learning_rate 5E-5
--epochs 1
--save_steps 2000
--eval_steps 100
--max_seq_length 64
--infer_with_fc_pooler
--dropout 0.2
--output_emb_size 256
--train_set_file "/home/aistudio/literature_search_data/recall/train_unsupervised.csv"
--test_set_file "/home/aistudio/literature_search_data/recall/dev.csv"
--model_name_or_path "rocketqa-zh-base-query-encoder"#查看数据并删除
#� /home/aistudio/simcse/checkpoint
#ls
# !mv xxx xx
# !rm -rf /home/aistudio/simcse/checkpointshell-init: 获取当前目录时出错: getcwd: 无法访问父目录: 没有那个文件或目录部分结果展示:
代码语言:txt复制global step 23960, epoch: 1, batch: 23960, loss: 0.00017, speed: 11.19 step/s
global step 23970, epoch: 1, batch: 23970, loss: 0.00014, speed: 11.18 step/s
global step 23980, epoch: 1, batch: 23980, loss: 0.00013, speed: 10.85 step/s
global step 23990, epoch: 1, batch: 23990, loss: 0.00012, speed: 10.28 step/s
global step 24000, epoch: 1, batch: 24000, loss: 0.00017, speed: 10.48 step/s
[2023-06-20 17:06:09,931] [ INFO] - tokenizer config file saved in ./checkpoints/model_24000/tokenizer_config.json
[2023-06-20 17:06:09,932] [ INFO] - Special tokens file saved in ./checkpoints/model_24000/special_tokens_map.json可支持配置的参数:
infer_with_fc_pooler:可选,在预测阶段计算文本 embedding 表示的时候网络前向是否会过训练阶段最后一层的 fc; 建议打开模型效果最好。scale:可选,在计算 cross_entropy loss 之前对 cosine 相似度进行缩放的因子;默认为 20。dropout:可选,SimCSE 网络前向使用的 dropout 取值;默认 0.1。save_dir:可选,保存训练模型的目录;默认保存在当前目录checkpoints文件夹下。max_seq_length:可选,ERNIE-Gram 模型使用的最大序列长度,最大不能超过512, 若出现显存不足,请适当调低这一参数;默认为128。batch_size:可选,批处理大小,请结合显存情况进行调整,若出现显存不足,请适当调低这一参数;默认为32。learning_rate:可选,Fine-tune的最大学习率;默认为5e-5。weight_decay:可选,控制正则项力度的参数,用于防止过拟合,默认为0.0。epochs: 训练轮次,默认为1。warmup_proption:可选,学习率warmup策略的比例,如果0.1,则学习率会在前10%训练step的过程中从0慢慢增长到learning_rate, 而后再缓慢衰减,默认为0.0。init_from_ckpt:可选,模型参数路径,热启动模型训练;默认为None。seed:可选,随机种子,默认为1000.device: 选用什么设备进行训练,可选cpu或gpu。如使用gpu训练则参数gpus指定GPU卡号。model_name_or_path: 预训练模型,用于模型和Tokenizer的参数初始化。
程序运行时将会自动进行训练,评估。同时训练过程中会自动保存模型在指定的save_dir中。
如:
代码语言:text复制checkpoints/
├── model_100
│ ├── model_state.pdparams
│ ├── tokenizer_config.json
│ └── vocab.txt
└── ...2.3 效果评估
效果评估分为 4 个步骤:
- a. 获取Doc端Embedding
基于语义索引模型抽取出Doc样本库的文本向量,
- b. 采用hnswlib对Doc端Embedding建库
使用 ANN 引擎构建索引库(这里基于 hnswlib 进行 ANN 索引)
- c. 获取Query的Embedding并查询相似结果
基于语义索引模型抽取出评估集 Source Text 的文本向量,在第 2 步中建立的索引库中进行 ANN 查询,召回 Top50 最相似的 Target Text, 产出评估集中 Source Text 的召回结果 recall_result 文件
- d. 评估
基于评估集 dev.csv 和召回结果 recall_result 计算评估指标 Recall@k,其中k取值1,5,10,20,50.
运行如下命令进行 ANN 建库、召回,产出召回结果数据 recall_result
也可以使用下面的bash脚本:
代码语言:txt复制sh scripts/run_build_index.shrun_build_index.sh还包含cpu和gpu运行的脚本,默认是gpu的脚本
代码语言:python代码运行次数:0复制!python -u -m paddle.distributed.launch --gpus "0" --log_dir "recall_log/"
recall.py
--device gpu
--recall_result_dir "recall_result_dir"
--recall_result_file "recall_result.txt"
--params_path "checkpoint/model_24000/model_state.pdparams"
--model_name_or_path rocketqa-zh-base-query-encoder
--hnsw_m 100
--hnsw_ef 100
--batch_size 32
--output_emb_size 256
--max_seq_length 60
--recall_num 50
--similar_text_pair "/home/aistudio/literature_search_data/recall/dev.csv"
--corpus_file "/home/aistudio/literature_search_data/recall/corpus.csv"LAUNCH INFO 2023-06-20 17:21:57,220 ----------- Configuration ----------------------LAUNCH INFO 2023-06-20 17:21:57,220 devices: 0LAUNCH INFO 2023-06-20 17:21:57,220 elastic_level: -1LAUNCH INFO 2023-06-20 17:21:57,220 elastic_timeout: 30LAUNCH INFO 2023-06-20 17:21:57,220 gloo_port: 6767LAUNCH INFO 2023-06-20 17:21:57,220 host: NoneLAUNCH INFO 2023-06-20 17:21:57,220 ips: NoneLAUNCH INFO 2023-06-20 17:21:57,220 job_id: defaultLAUNCH INFO 2023-06-20 17:21:57,220 legacy: FalseLAUNCH INFO 2023-06-20 17:21:57,220 log_dir: recall_log/LAUNCH INFO 2023-06-20 17:21:57,220 log_level: INFOLAUNCH INFO 2023-06-20 17:21:57,220 master: NoneLAUNCH INFO 2023-06-20 17:21:57,220 max_restart: 3LAUNCH INFO 2023-06-20 17:21:57,220 nnodes: 1LAUNCH INFO 2023-06-20 17:21:57,220 nproc_per_node: NoneLAUNCH INFO 2023-06-20 17:21:57,220 rank: -1LAUNCH INFO 2023-06-20 17:21:57,220 run_mode: collectiveLAUNCH INFO 2023-06-20 17:21:57,220 server_num: NoneLAUNCH INFO 2023-06-20 17:21:57,220 servers: LAUNCH INFO 2023-06-20 17:21:57,220 start_port: 6070LAUNCH INFO 2023-06-20 17:21:57,220 trainer_num: NoneLAUNCH INFO 2023-06-20 17:21:57,220 trainers: LAUNCH INFO 2023-06-20 17:21:57,220 training_script: recall.pyLAUNCH INFO 2023-06-20 17:21:57,220 training_script_args: ['--device', 'gpu', '--recall_result_dir', 'recall_result_dir', '--recall_result_file', 'recall_result.txt', '--params_path', 'checkpoint/model_24000/model_state.pdparams', '--model_name_or_path', 'rocketqa-zh-base-query-encoder', '--hnsw_m', '100', '--hnsw_ef', '100', '--batch_size', '32', '--output_emb_size', '256', '--max_seq_length', '60', '--recall_num', '50', '--similar_text_pair', '/home/aistudio/literature_search_data/recall/dev.csv', '--corpus_file', '/home/aistudio/literature_search_data/recall/corpus.csv']LAUNCH INFO 2023-06-20 17:21:57,220 with_gloo: 1LAUNCH INFO 2023-06-20 17:21:57,220 --------------------------------------------------LAUNCH INFO 2023-06-20 17:21:57,221 Job: default, mode collective, replicas 1[1:1], elastic FalseLAUNCH INFO 2023-06-20 17:21:57,228 Run Pod: zkzrka, replicas 1, status readyLAUNCH INFO 2023-06-20 17:21:57,241 Watching Pod: zkzrka, replicas 1, status running[2023-06-20 17:21:59,871] [ INFO] - We are using <class 'paddlenlp.transformers.ernie.tokenizer.ErnieTokenizer'> to load 'rocketqa-zh-base-query-encoder'.[2023-06-20 17:21:59,871] [ INFO] - Already cached /home/aistudio/.paddlenlp/models/rocketqa-zh-base-query-encoder/ernie_3.0_base_zh_vocab.txt[2023-06-20 17:21:59,894] [ INFO] - tokenizer config file saved in /home/aistudio/.paddlenlp/models/rocketqa-zh-base-query-encoder/tokenizer_config.json[2023-06-20 17:21:59,894] [ INFO] - Special tokens file saved in /home/aistudio/.paddlenlp/models/rocketqa-zh-base-query-encoder/special_tokens_map.json[2023-06-20 17:21:59,895] [ INFO] - We are using <class 'paddlenlp.transformers.ernie.modeling.ErnieModel'> to load 'rocketqa-zh-base-query-encoder'.[2023-06-20 17:21:59,896] [ INFO] - Model config ErnieConfig { "attention_probs_dropout_prob": 0.1, "enable_recompute": false, "fuse": false, "hidden_act": "gelu", "hidden_dropout_prob": 0.1, "hidden_size": 768, "initializer_range": 0.02, "intermediate_size": 3072, "layer_norm_eps": 1e-12, "max_position_embeddings": 2048, "model_type": "ernie", "num_attention_heads": 12, "num_hidden_layers": 12, "pad_token_id": 0, "paddlenlp_version": null, "pool_act": "tanh", "task_id": 0, "task_type_vocab_size": 3, "type_vocab_size": 4, "use_task_id": true, "vocab_size": 40000}W0620 17:22:01.903739 113876 gpu_resources.cc:61] Please NOTE: device: 0, GPU Compute Capability: 8.0, Driver API Version: 11.2, Runtime API Version: 11.2W0620 17:22:01.906452 113876 gpu_resources.cc:91] device: 0, cuDNN Version: 8.2.[2023-06-20 17:22:02,567] [ WARNING] - Some weights of the model checkpoint at rocketqa-zh-base-query-encoder were not used when initializing ErnieModel: ['classifier.bias', 'classifier.weight']- This IS expected if you are initializing ErnieModel from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model).
- This IS NOT expected if you are initializing ErnieModel from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).
[2023-06-20 17:22:02,568] [ INFO] - All the weights of ErnieModel were initialized from the model checkpoint at rocketqa-zh-base-query-encoder.
If your task is similar to the task the model of the checkpoint was trained on, you can already use ErnieModel for predictions without further training.
[2023-06-20 17:22:03,384] [ INFO] - Loaded parameters from checkpoint/model_24000/model_state.pdparams
[2023-06-20 17:22:03,684] [ INFO] - start build index..........
[2023-06-20 17:25:12,817] [ INFO] - Total index number:300000
LAUNCH INFO 2023-06-20 17:25:57,498 Pod completed
LAUNCH INFO 2023-06-20 17:25:57,499 Exit code 0#接下来,运行如下命令进行效果评估,产出Recall@1, Recall@5, Recall@10, Recall@20 和 Recall@50 指标:
#recall_num = [1, 5, 10, 20, 50] 可以在程序里修改
!python -u evaluate.py
--similar_text_pair "/home/aistudio/literature_search_data/recall/dev.csv"
--recall_result_file "./recall_result_dir/recall_result.txt"
--recall_num 50recall@1=46.226recall@5=58.91recall@10=63.107recall@20=67.23recall@50=72.13也可以使用下面的bash脚本:
代码语言:txt复制bash scripts/evaluate.sh参数含义说明
similar_text_pair: 由相似文本对构成的评估集recall_result_file: 针对评估集中第一列文本 Source Text 的召回结果recall_num: 对 1 个文本召回的相似文本数量
成功运行结束后,会输出如下评估指标:
代码语言:txt复制recall@1=46.226
recall@5=58.91
recall@10=63.107
recall@20=67.23
recall@50=72.132.4. 预测
我们可以基于语义索引模型预测文本的语义向量或者计算文本 Pair 的语义相似度。
2.4.1 功能一:抽取文本的语义向量
修改 inference.py 文件里面输入文本 id2corpus 和模型路径 params_path:
params_path='checkpoints/model_12000/model_state.pdparams'
id2corpus={0:'国有企业引入非国有资本对创新绩效的影响——基于制造业国有上市公司的经验证据'}
代码语言:txt复制然后运行
```python!python inference.py
代码语言:txt复制预测结果位256维的向量:1, 256
[[ 4.23777066e-02 1.34486571e-01 -3.58039439e-02 -4.98685837e-02
9.64262784e-02 3.75175267e-03 1.15876347e-01 5.15929982e-03
5.40714264e-02 -8.27478245e-02 -8.87063593e-02 -7.43068382e-02
-2.28806712e-05 -8.13025162e-02 -1.69725120e-02 -4.51577082e-02
...
代码语言:txt复制### 2.4.2 功能二:计算文本 Pair 的语义相似度
* 准备预测数据
待预测数据为 tab 分隔的 tsv 文件,每一行为 1 个文本 Pair,部分示例如下:热处理对尼龙6 及其与聚酰胺嵌段共聚物共混体系晶体熔融行为和结晶结构的影响 热处理对尼龙6及其与聚酰胺嵌段共聚物共混体系晶体熔融行为和结晶结构的影响尼龙6,聚酰胺嵌段共聚物,芳香聚酰胺,热处理
面向生态系统服务的生态系统分类方案研发与应用. 面向生态系统服务的生态系统分类方案研发与应用
huntington舞蹈病的动物模型 Huntington舞蹈病的动物模型
试论我国海岸带经济开发的问题与前景 试论我国海岸带经济开发的问题与前景海岸带,经济开发,问题,前景
代码语言:txt复制* 开始预测
以上述 demo 数据为例,运行如下命令基于我们开源的 SimCSE无监督语义索引模型开始计算文本 Pair 的语义相似度:
```python!python -u -m paddle.distributed.launch --gpus "0"
代码语言:txt复制predict.py --device gpu --params_path "/home/aistudio/simcse/checkpoint/model_24000/model_state.pdparams" --model_name_or_path rocketqa-zh-base-query-encoder --output_emb_size 256 --batch_size 128 --max_seq_length 64 --text_pair_file "/home/aistudio/literature_search_data/recall/test.csv"参数含义说明
* `device`: 使用 cpu/gpu 进行训练
* `params_path`: 预训练模型的参数文件名
* `model_name_or_path`: 预训练模型,用于模型和`Tokenizer`的参数初始化。
* `output_emb_size`: Transformer 顶层输出的文本向量维度
* `text_pair_file`: 由文本 Pair 构成的待预测数据集
也可以运行下面的bash脚本:sh scripts/predict.sh
代码语言:txt复制产出如下结果0.8776634931564331
0.22624854743480682
0.1711222529411316
0.35435163974761963
...
代码语言:txt复制## 2.5.推理部署
### 2.5.1 动转静导出
首先把动态图模型转换为静态图:
也可以运行下面的bash脚本:sh scripts/export_model.sh
代码语言:txt复制```python!python export_model.py --params_path checkpoints/model_24000/model_state.pdparams
代码语言:txt复制 --model_name_or_path rocketqa-zh-base-query-encoder --output_path=./output [32m[2023-06-20 17:38:38,694] [ INFO][0m - We are using <class 'paddlenlp.transformers.ernie.modeling.ErnieModel'> to load 'rocketqa-zh-base-query-encoder'.[0m
[32m[2023-06-20 17:38:38,695] [ INFO][0m - Model config ErnieConfig {
"attention_probs_dropout_prob": 0.1,
"enable_recompute": false,
"fuse": false,
"hidden_act": "gelu",
"hidden_dropout_prob": 0.1,
"hidden_size": 768,
"initializer_range": 0.02,
"intermediate_size": 3072,
"layer_norm_eps": 1e-12,
"max_position_embeddings": 2048,
"model_type": "ernie",
"num_attention_heads": 12,
"num_hidden_layers": 12,
"pad_token_id": 0,
"paddlenlp_version": null,
"pool_act": "tanh",
"task_id": 0,
"task_type_vocab_size": 3,
"type_vocab_size": 4,
"use_task_id": true,
"vocab_size": 40000
}
[0m
W0620 17:38:40.708287 136862 gpu_resources.cc:61] Please NOTE: device: 0, GPU Compute Capability: 8.0, Driver API Version: 11.2, Runtime API Version: 11.2
W0620 17:38:40.711041 136862 gpu_resources.cc:91] device: 0, cuDNN Version: 8.2.
[33m[2023-06-20 17:38:41,352] [ WARNING][0m - Some weights of the model checkpoint at rocketqa-zh-base-query-encoder were not used when initializing ErnieModel: ['classifier.weight', 'classifier.bias']
- This IS expected if you are initializing ErnieModel from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model).
- This IS NOT expected if you are initializing ErnieModel from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).[0m
[32m[2023-06-20 17:38:41,353] [ INFO][0m - All the weights of ErnieModel were initialized from the model checkpoint at rocketqa-zh-base-query-encoder.
If your task is similar to the task the model of the checkpoint was trained on, you can already use ErnieModel for predictions without further training.[0m
[32m[2023-06-20 17:38:41,353] [ INFO][0m - We are using <class 'paddlenlp.transformers.ernie.tokenizer.ErnieTokenizer'> to load 'rocketqa-zh-base-query-encoder'.[0m
[32m[2023-06-20 17:38:41,353] [ INFO][0m - Already cached /home/aistudio/.paddlenlp/models/rocketqa-zh-base-query-encoder/ernie_3.0_base_zh_vocab.txt[0m
[32m[2023-06-20 17:38:41,375] [ INFO][0m - tokenizer config file saved in /home/aistudio/.paddlenlp/models/rocketqa-zh-base-query-encoder/tokenizer_config.json[0m
[32m[2023-06-20 17:38:41,375] [ INFO][0m - Special tokens file saved in /home/aistudio/.paddlenlp/models/rocketqa-zh-base-query-encoder/special_tokens_map.json[0m
[0m
## 2.6 Paddle Inference预测
预测既可以抽取向量也可以计算两个文本的相似度。
修改id2corpus的样本:#抽取向量
id2corpus={0:'国有企业引入非国有资本对创新绩效的影响——基于制造业国有上市公司的经验证据'}
#计算相似度
corpus_list=['中西方语言与文化的差异','中西方文化差异以及语言体现中西方文化,差异,语言体现',
代码语言:txt复制 ['中西方语言与文化的差异','飞桨致力于让深度学习技术的创新与应用更简单']]然后使用PaddleInference:
也可以运行下面的bash脚本:sh deploy.sh
代码语言:txt复制```python!python deploy/python/predict.py --model_dir=./output
代码语言:txt复制最终输出的是256维度的特征向量和句子对的预测概率:(1, 256)
[[ 3.75502072e-02 3.84643604e-03 8.99736658e-02 1.26044407e-01
-5.82645983e-02 1.04881898e-01 1.18444994e-01 -1.79638471e-02
-9.96992644e-03 5.86171634e-02 7.59094805e-02 -6.29124865e-02
.......
0.9356030821800232, 0.4809684753417969
代码语言:txt复制# 3.DiffCSE(Unsupervised):2022.04模型无监督训练下效果
**相比于 SimCSE 模型,DiffCSE模型会更关注语句之间的差异性,具有精确的向量表示能力。DiffCSE 模型同样适合缺乏监督数据,但是又有大量无监督数据的匹配和检索场景。**
https://arxiv.org/pdf/2204.10298.pdf
结合句子间差异的无监督句子嵌入对比学习方法——DiffCSE主要还是在SimCSE上进行优化(可见SimCSE的重要性),通过ELECTRA模型的生成伪造样本和RTD(Replaced Token Detection)任务,来学习原始句子与伪造句子之间的差异,以提高句向量表征模型的效果。
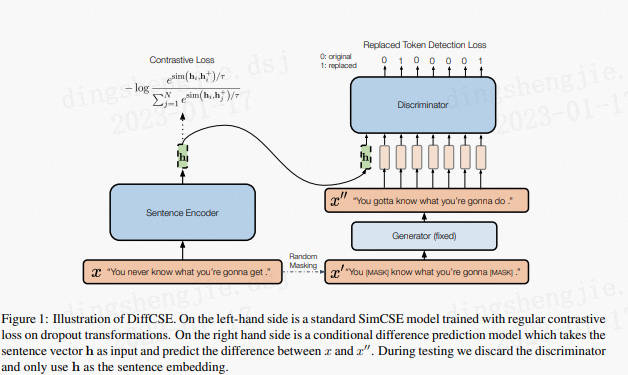
其思想同样来自于CV领域(采用不变对比学习和可变对比学习相结合的方法可以提高图像表征的效果)。作者提出使用基于dropout masks机制的增强作为不敏感转换学习对比学习损失和基于MLM语言模型进行词语替换的方法作为敏感转换学习「原始句子与编辑句子」之间的差异,共同优化句向量表征。
在SimCSE模型中,采用pooler层(一个带有tanh激活函数的全连接层)作为句子向量输出。该论文发现,采用带有BN的两层pooler效果更为突出,BN在SimCSE模型上依然有效。
- ①对于掩码概率,经实验发现,在掩码概率为30%时,模型效果最优。
- ②针对两个损失之间的权重值,经实验发现,对比学习损失为RTD损失200倍时,模型效果最优。
```python!unzip -d /home/aistudio /home/aistudio/diffcse.zip
代码语言:txt复制 Archive: /home/aistudio/diffcse.zip
creating: /home/aistudio/diffcse/
inflating: /home/aistudio/diffcse/custom_ernie.py
inflating: /home/aistudio/diffcse/data.py
inflating: /home/aistudio/diffcse/model.py
inflating: /home/aistudio/diffcse/README.md
inflating: /home/aistudio/diffcse/run_diffcse.py
inflating: /home/aistudio/diffcse/run_eval.sh
inflating: /home/aistudio/diffcse/run_infer.sh
inflating: /home/aistudio/diffcse/run_train.sh
inflating: /home/aistudio/diffcse/utils.py
```python!unzip -d /home/aistudio /home/aistudio/senteval_cn.zip
代码语言:txt复制```python� /home/aistudio/diffcse
代码语言:txt复制 /home/aistudio/diffcse
```python!python -u -m paddle.distributed.launch --gpus '0' --log_dir "log_train"
代码语言:txt复制run_diffcse.py --mode "train" --encoder_name "rocketqa-zh-dureader-query-encoder" --generator_name "ernie-3.0-base-zh" --discriminator_name "ernie-3.0-base-zh" --max_seq_length "128" --output_emb_size "32" --train_set_file "/home/aistudio/LCQMC/train.txt" --eval_set_file "/home/aistudio/LCQMC/dev.tsv" --save_dir "./checkpoint" --log_dir "log_train" --save_steps "2000" --eval_steps "1000" --epochs "1" --batch_size "16" --mlm_probability "0.15" --lambda_weight "0.15" --learning_rate "3e-5" --weight_decay "0.01" --warmup_proportion "0.01" --seed "0" --device "gpu"#模型评估
!export CUDA_VISIBLE_DEVICES
!python -u -m paddle.distributed.launch --gpus "0" --log_dir "log_eval"
代码语言:txt复制run_diffcse.py --mode "eval" --encoder_name "rocketqa-zh-dureader-query-encoder" --max_seq_length "128" --output_emb_size "32" --eval_set_file "/home/aistudio/LCQMC/dev.tsv" --ckpt_dir "/home/aistudio/diffcse/checkpoint/best" --batch_size "16" --seed "0" --device "gpu"4.总结
语义索引(可通俗理解为向量索引)技术是搜索引擎、推荐系统、广告系统在召回阶段的核心技术之一。语义索引模型的目标是:给定输入文本,模型可以从海量候选召回库中快速、准确地召回一批语义相关文本。语义索引模型的效果直接决定了语义相关的物料能否被成功召回进入系统参与上层排序,从基础层面影响整个系统的效果。
在召回阶段,最常见的方式是通过双塔模型,学习Document(简写为Doc)的向量表示,对Doc端建立索引,用ANN召回。我们在这种方式的基础上,引入无监督预训练策略,SimCSE 模型适合缺乏监督数据,但是又有大量无监督数据的匹配和检索场景。
- 更多文本匹配方案参考:
1. [特定领域知识图谱融合方案:技术知识前置【一】-文本匹配算法:](https://blog.csdn.net/sinat_39620217/article/details/128718537)2. [特定领域知识图谱融合方案:文本匹配算法Simnet、Diffcse【二】:](https://blog.csdn.net/sinat_39620217/article/details/128833057)3. [特定领域知识图谱融合方案:文本匹配算法ERNIE-Gram单塔等诸多模型【三】:](https://blog.csdn.net/sinat_39620217/article/details/129026570)4. [基于文心大模型套件ERNIEKit实现文本匹配算法:](https://blog.csdn.net/sinat_39620217/article/details/129031252)5. [特定领域知识图谱融合方案:学以致用-问题匹配鲁棒性评测比赛验证【四】:](https://blog.csdn.net/sinat_39620217/article/details/129026193)相比于 SimCSE 模型,DiffCSE模型会更关注语句之间的差异性,具有精确的向量表示能力。DiffCSE 模型同样适合缺乏监督数据,但是又有大量无监督数据的匹配和检索场景。更多优质内容请关注公号:汀丶人工智能
Reference
1 Gao, Tianyu, Xingcheng Yao, and Danqi Chen. “SimCSE: Simple Contrastive Learning of Sentence Embeddings.” ArXiv:2104.08821 Cs, April 18, 2021. http://arxiv.org/abs/2104.08821.

