
大家好,又见面了,我是你们的朋友全栈君。
1. ElasticSearch快速入门
1.1. 基本介绍
- ElasticSearch特色
Elasticsearch是实时的分布式搜索分析引擎,内部使用Lucene做索引与搜索
- 实时性:新增到 ES 中的数据在1秒后就可以被检索到,这种新增数据对搜索的可见性称为“准实时搜索”
- 分布式:意味着可以动态调整集群规模,弹性扩容
- 集群规模:可以扩展到上百台服务器,处理PB级结构化或非结构化数据
- 各节点组成对等的网络结构,某些节点出现故障时会自动分配其他节点代替其进行工作
Lucene是Java语言编写的全文搜索框架,用于处理纯文本的数据,但它只是一个库,提供建立索引、执行搜索等接口,但不包含分布式服务,这些正是 ES 做的
- ElasticSearch使用场景
ElasticSearch广泛应用于各行业领域, 比如维基百科, GitHub的代码搜索,电商网站的大数据日志统计分析, BI系统报表统计分析等。
- 提供分布式的搜索引擎和数据分析引擎 比如百度,网站的站内搜索,IT系统的检索, 数据分析比如热点词统计, 电商网站商品TOP排名等。
- 全文检索,结构化检索,数据分析 支持全文检索, 比如查找包含指定名称的商品信息; 支持结构检索, 比如查找某个分类下的所有商品信息; 还可以支持高级数据分析, 比如统计某个商品的点击次数, 某个商品有多少用户购买等等。
- 支持海量数据准实时的处理 采用分布式节点, 将数据分散到多台服务器上去存储和检索, 实现海量数据的处理, 比如统计用户的行为日志, 能够在秒级别对数据进行检索和分析。
- ElasticSearch基本概念介绍
ElasticSearch Relational Database Index Database Type Table Document Row Field Column Mapping Schema Everything is indexed Index Query DSL SQL GET http://… SELECT * FROM table… PUT http://… UPDATE table SET…
- 索引(Index) 相比传统的关系型数据库,索引相当于SQL中的一个【数据库】,或者一个数据存储方案(schema)。
- 类型(Type) 一个索引内部可以定义一个或多个类型, 在传统关系数据库来说, 类型相当于【表】的概念。
- 文档(Document) 文档是Lucene索引和搜索的原子单位,它是包含了一个或多个域的容器,采用JSON格式表示。相当于传统数据库【行】概念
- 集群(Cluster) 集群是由一台及以上主机节点组成并提供存储及搜索服务, 多节点组成的集群拥有冗余能力,它可以在一个或几个节点出现故障时保证服务的整体可用性。
- 节点(Node) Node为集群中的单台节点,其可以为master节点亦可为slave节点(节点属性由集群内部选举得出)并提供存储相关数据的功能
- 切片(shards) 切片是把一个大文件分割成多个小文件然后分散存储在集群中的多个节点上, 可以将其看作mysql的分库分表概念。 Shard有两种类型:primary主片和replica副本,primary用于文档存储,每个新的索引会自动创建5个Primary shard;Replica shard是Primary Shard的副本,用于冗余数据及提高搜索性能。

注意: ES7之后Type被舍弃,只有Index(等同于数据库 表定义)和Document(文档,行记录)。
1.2 ElasticSearch安装
下载ElasticSearch服务
下载最新版ElasticSearch7.10.2: https://www.elastic.co/cn/start
解压安装包
代码语言:javascript复制tar -xvf elasticsearch-7.10.2-linux-x86_64.tar.gzElasticSearch不能以Root身份运行, 需要单独创建一个用户
代码语言:javascript复制1. groupadd elsearch
2. useradd elsearch -g elsearch -p elasticsearch
3. chown -R elsearch:elsearch /usr/local/elasticsearch-7.10.2执行以上命令,创建一个名为elsearch用户, 并赋予目录权限。
修改配置文件
vi config/elasticsearch.yml, 默认情况下会绑定本机地址, 外网不能访问, 这里要修改下:
代码语言:javascript复制# 外网访问地址
network.host: 0.0.0.0关闭防火墙
代码语言:javascript复制systemctl stop firewalld.service
systemctl disable firewalld.service指定JDK版本
最新版的ElasticSearch需要JDK11版本, 下载JDK11压缩包, 并进行解压。
修改环境配置文件
vi bin/elasticsearch-env
参照以下位置, 追加一行, 设置JAVA_HOME, 指定JDK11路径。
代码语言:javascript复制JAVA_HOME=/usr/local/jdk-11.0.11
# now set the path to java
if [ ! -z "$JAVA_HOME" ]; then
JAVA="$JAVA_HOME/bin/java"
else
if [ "$(uname -s)" = "Darwin" ]; then
# OSX has a different structure
JAVA="$ES_HOME/jdk/Contents/Home/bin/java"
else
JAVA="$ES_HOME/jdk/bin/java"
fi
fi- 启动ElasticSearch
- 切换用户 su elsearch
- 以后台常驻方式启动 bin/elasticsearch -d
问题记录
出现max virtual memory areas vm.max_map_count [65530] is too low, increase to at least 错误信息
修改系统配置:
vi /etc/sysctl.conf
添加
vm.max_map_count=655360
执行生效
sysctl -p
vi /etc/security/limits.conf
在文件末尾添加
代码语言:javascript复制* soft nofile 65536
* hard nofile 131072
* soft nproc 2048
* hard nproc 4096
elsearch soft nproc 125535
elsearch hard nproc 125535重新切换用户即可:
su – elsearch
访问验证
访问地址:http://192.168.116.140:9200/_cat/health

启动状态有green、yellow和red。 green是代表启动正常。
1.3 Kibana服务安装
Kibana是一个针对Elasticsearch的开源分析及可视化平台,用来搜索、查看交互存储在Elasticsearch索引中的数据。
到官网下载, Kibana安装包, 与之对应7.10.2版本, 选择Linux 64位版本下载,并进行解压。
代码语言:javascript复制tar -xvf kibana-7.10.2-linux-x86_64.tar.gzKibana启动不能使用root用户, 使用上面创建的elsearch用户, 进行赋权:
代码语言:javascript复制chown -R elsearch:elsearch kibana-7.10.2-linux-x86_64修改配置文件
vi config/kibana.yml , 修改以下配置:
代码语言:javascript复制# 服务端口
server.port: 5601
# 服务地址
server.host: "0.0.0.0"
# elasticsearch服务地址
elasticsearch.hosts: ["http://192.168.116.140:9200"]启动kibana
代码语言:javascript复制./kibana -q看到以下日志, 代表启动正常
代码语言:javascript复制log [01:40:00.143] [info][listening] Server running at http://0.0.0.0:5601如果出现启动失败的情况, 要检查集群各节点的日志, 确保服务正常运行状态。
访问服务
http://192.168.116.140:5601/app/home#/
1.4 ES的基础操作
- 进入Kibana管理后台 地址: http://192.168.116.140:5601 进入”Dev Tools”栏:

在Console中输入命令进行操作。
分片设置:
这里增加名为orders的索引, 因为是单节点, 如果副本数, 是会出现错误。
代码语言:javascript复制PUT orders
{
"settings": {
"index": {
"number_of_shards": 2,
"number_of_replicas": 2
}
}
}查看索引信息, 会出现yellow提示:

因为单节点模式, 只有主节点信息:
删除重新创建:
代码语言:javascript复制PUT orders
{
"settings": {
"index": {
"number_of_shards": 2,
"number_of_replicas": 0
}
}
}将分片数设为0, 再次查看, 则显示正常:

索引
3.1 新建索引orders
代码语言:javascript复制## 创建索引
PUT orders3.2 查询索引orders
代码语言:javascript复制## 查询索引
GET orders
通过查询命令, 能查看到对应信息, 默认分片数和副本数都为1:
代码语言:javascript复制 "number_of_shards" : "1", ## 主分片数
"number_of_replicas" : "1", ## 副分片数
3.3 删除索引
代码语言:javascript复制 ## 删除索引
DELETE orders3.4 索引的设置
代码语言:javascript复制 ## 设置索引
PUT orders
{
"settings": {
"index": {
"number_of_shards": 1,
"number_of_replicas": 0
}
}
}文档
4.1 创建文档
代码语言:javascript复制## 创建文档,生成默认的文档id
POST orders/_doc
{
"name": "袜子1双",
"price": "200",
"count": 1,
"address": "北京市"
}
## 创建文档,生成自定义文档id
POST orders/_doc/1
{
"name": "袜子1双",
"price": "2",
"count": 1,
"address": "北京市"
}4.2 查询文档
代码语言:javascript复制## 根据指定的id查询
GET orders/_doc/1
## 根据指定条件查询文档
GET orders/_search
{
"query": {
"match": {
"address": "北京市"
}
}
}
## 查询全部文档
GET orders/_search4.3 更新文档
代码语言:javascript复制## 更新文档
POST orders/_doc/1
{
"price": "200"
}
## 更新文档
POST orders/_update/1
{
"doc": {
"price": "200"
}
}4.4 删除文档
代码语言:javascript复制## 删除文档
DELETE orders/_doc/1域
对于映射,只能进行字段添加,不能对字段进行修改或删除,如有需要,则重新创建映射。
代码语言:javascript复制## 设置mapping信息
PUT orders/_mappings
{
"properties":{
"price": {
"type": "long"
}
}
}
## 设置分片和映射
PUT orders
{
"settings": {
"index": {
"number_of_shards": 1,
"number_of_replicas": 0
}
},
"mappings": {
"properties": {
"name": {
"type": "text"
},
"price": {
"type": "long"
},
"count": {
"type": "long"
},
"address": {
"type": "text"
}
}
}
}1.5 ES数据类型
整体数据类型结构:

String 类型
主要分为text与keyword两种类型。两者区别主要在于能否分词。
- text类型 会进行分词处理, 分词器默认采用的是standard。
- keyword类型 不会进行分词处理。在ES的倒排索引中存储的是完整的字符串。
Date时间类型
数据库里的日期类型需要规范具体的传入格式, ES是可以控制,自适应处理。
传递不同的时间类型:
代码语言:javascript复制PUT my_date_index/_doc/1
{ "date": "2021-01-01" }
PUT my_date_index/_doc/2
{ "date": "2021-01-01T12:10:30Z" }
PUT my_date_index/_doc/3
{ "date": 1520071600001 } 查看日期数据:
GET my_date_index/_mapping
代码语言:javascript复制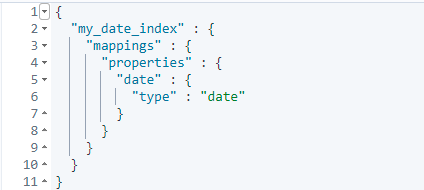
ES的Date类型允许可以使用的格式有:
> yyyy-MM-dd HH:mm:ss
> yyyy-MM-dd
> epoch_millis(毫秒值)
3. 复合类型
复杂类型主要有三种: Array、object、nested。
Array类型: 在Elasticsearch中,数组不需要声明专用的字段数据类型。但是,在数组中的所有值都必须具有相同的数据类型。举例:
```sh
POST orders/_doc/1
{
"goodsName":["足球","篮球","兵乓球", 3]
}
POST orders/_doc/1
{
"goodsName":["足球","篮球","兵乓球"]
}
```
object类型: 用于存储单个JSON对象, 类似于JAVA中的对象类型, 可以有多个值, 比如LIST<object>,可以包含多个对象。
但是LIST<object>只能作为整体, 不能独立的索引查询。举例:
```sh
# 新增第一组数据, 组别为美国,两个人。
POST my_index/_doc/1
{
"group" : "america",
"users" : [
{
"name" : "John",
"age" : "22"
},
{
"name" : "Alice",
"age" : "21"
}
]
}
# 新增第二组数据, 组别为英国, 两个人。
POST my_index/_doc/2
{
"group" : "england",
"users" : [
{
"name" : "lucy",
"age" : "21"
},
{
"name" : "John",
"age" : "32"
}
]
}
```
这两组数据都包含了name为John,age为21的数据,
采用这个搜索条件, 实际结果:
```sh
GET my_index/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"users.name": "John"
}
},
{
"match": {
"users.age": "21"
}
}
]
}
}
}
```
结果可以看到, 这两组数据都能找出,因为每一组数据都是作为一个整体进行搜索匹配, 而非具体某一条数据。
Nested类型
用于存储多个JSON对象组成的数组,`nested` 类型是 `object` 类型中的一个特例,可以让对象数组独立索引和查询。
举例:
创建nested类型的索引:
```sh
PUT my_index
{
"mappings": {
"properties": {
"users": {
"type": "nested"
}
}
}
}
```
发出查询请求:
```sh
GET my_index/_search
{
"query": {
"bool": {
"must": [
{
"nested": {
"path": "users",
"query": {
"bool": {
"must": [
{
"match": {
"users.name": "John"
}
},
{
"match": {
"users.age": "21"
}
}
]
}
}
}
}
]
}
}
}
```
采用以前的条件, 这个时候查不到任何结果, 将年龄改成22, 就可以找出对应的数据:
```sh
"hits" : [
{
"_index" : "my_index",
"_type" : "_doc",
"_id" : "1",
"_score" : 1.89712,
"_source" : {
"group" : "america",
"users" : [
{
"name" : "John",
"age" : "22"
},
{
"name" : "Alice",
"age" : "21"
}
]
}
}
]
```
4. GEO地理位置类型
现在大部分APP都有基于位置搜索的功能, 比如交友、购物应用等。这些功能是基于GEO搜索实现的。
对于GEO地理位置类型,分为地理坐标类型:Geo-point, 和形状:Geo-shape 两种类型。
| 经纬度 | 英文 | 简写 | 正数 | 负数 |
| :----- | :-------- | :------- | :--- | ---- |
| 维度 | latitude | lat | 北纬 | 南纬 |
| 经度 | longitude | lon或lng | 东经 | 西经 |
创建地理位置索引:
```sh
PUT my_locations
{
"mappings": {
"properties": {
"location": {
"type": "geo_point"
}
}
}
}
```
添加地理位置数据:
```sh
# 采用object对象类型
PUT my_locations/_doc/1
{
"user": "张三",
"text": "Geo-point as an object",
"location": {
"lat": 41.12,
"lon": -71.34
}
}
# 采用string类型
PUT my_locations/_doc/2
{
"user": "李四",
"text": "Geo-point as a string",
"location": "45.12,-75.34"
}
# 采用geohash类型(geohash算法可以将多维数据映射为一串字符)
PUT my_locations/_doc/3
{
"user": "王二麻子",
"text": "Geo-point as a geohash",
"location": "drm3btev3e86"
}
# 采用array数组类型
PUT my_locations/_doc/4
{
"user": "木头老七",
"text": "Geo-point as an array",
"location": [
-80.34,
51.12
]
}
```
需求:搜索出距离我{"lat" : 40,"lon" : -70} 200km范围内的人:
```sh
GET my_locations/_search
{
"query": {
"bool": {
"must": {
"match_all": {}
},
"filter": {
"geo_distance": {
"distance": "200km",
"location": {
"lat": 40,
"lon": -70
}
}
}
}
}
}
```
## 2. ES高可用集群配置
### 2.1 ElasticSearch集群介绍
**主节点(或候选主节点)**
主节点负责创建索引、删除索引、分配分片、追踪集群中的节点状态等工作, 主节点负荷相对较轻, 客户端请求可以直接发往任何节点, 由对应节点负责分发和返回处理结果。
一个节点启动之后, 采用 Zen Discovery机制去寻找集群中的其他节点, 并与之建立连接, 集群会从候选主节点中选举出一个主节点, 并且一个集群只能选举一个主节点, 在某些情况下, 由于网络通信丢包等问题, 一个集群可能会出现多个主节点, 称为“脑裂现象”, 脑裂会存在丢失数据的可能, 因为主节点拥有最高权限, 它决定了什么时候可以创建索引, 分片如何移动等, 如果存在多个主节点, 就会产生冲突, 容易产生数据丢失。要尽量避免这个问题, 可以通过 discovery.zen.minimum_master_nodes 来设置最少可工作的候选主节点个数。 建议设置为(候选主节点/2) 1 比如三个候选主节点,该配置项为 (3/2) 1 ,来保证集群中有半数以上的候选主节点, 没有足够的master候选节点, 就不会进行master节点选举,减少脑裂的可能。
主节点的参数设置:
```sh
node.master = true
node.data = false数据节点
数据节点负责数据的存储和CRUD等具体操作,数据节点对机器配置要求比较高、,首先需要有足够的磁盘空间来存储数据,其次数据操作对系统CPU、Memory和IO的性能消耗都很大。通常随着集群的扩大,需要增加更多的数据节点来提高可用性。
数据节点的参数设置:
代码语言:javascript复制node.master = false
node.data = true客户端节点
客户端节点不做候选主节点, 也不做数据节点的节点,只负责请求的分发、汇总等等,增加客户端节点类型更多是为了负载均衡的处理。
代码语言:javascript复制node.master = false
node.data = false提取节点(预处理节点)
能执行预处理管道,有自己独立的任务要执行, 在索引数据之前可以先对数据做预处理操作, 不负责数据存储也不负责集群相关的事务。
参数设置:
代码语言:javascript复制node.ingest = true协调节点
协调节点,是一种角色,而不是真实的Elasticsearch的节点,不能通过配置项来指定哪个节点为协调节点。集群中的任何节点,都可以充当协调节点的角色。当一个节点A收到用户的查询请求后,会把查询子句分发到其它的节点,然后合并各个节点返回的查询结果,最后返回一个完整的数据集给用户。在这个过程中,节点A扮演的就是协调节点的角色。
ES的一次请求非常类似于Map-Reduce操作。在ES中对应的也是两个阶段,称之为scatter-gather。客户端发出一个请求到集群的任意一个节点,这个节点就是所谓的协调节点,它会把请求转发给含有相关数据的节点(scatter阶段),这些数据节点会在本地执行请求然后把结果返回给协调节点。协调节点将这些结果汇总(reduce)成一个单一的全局结果集(gather阶段) 。
部落节点
在多个集群之间充当联合客户端, 它是一个特殊的客户端 , 可以连接多个集群,在所有连接的集群上执行搜索和其他操作。 部落节点从所有连接的集群中检索集群状态并将其合并成全局集群状态。 掌握这一信息,就可以对所有集群中的节点执行读写操作,就好像它们是本地的。 请注意,部落节点需要能够连接到每个配置的集群中的每个单个节点。
2.2 ElasticSearch集群原理
2.2.1 集群分布式原理
ES集群可以根据节点数, 动态调整主分片与副本数, 做到整个集群有效均衡负载。
单节点状态下:

两个节点状态下, 副本数为1:

三个节点状态下, 副本数为1:

三个节点状态下, 副本数为2:

2.2.2 分片处理机制
设置分片大小的时候, 需预先做好容量规划, 如果节点数过多, 分片数过小, 那么新的节点将无法分片, 不能做到水平扩展, 并且单个分片数据量太大, 导致数据重新分配耗时过大。
假设一个集群中有一个主节点、两个数据节点。orders索引的分片分布情况如下所示:
代码语言:javascript复制PUT orders
{
"settings":{
"number_of_shards":2, ## 主分片 2
"number_of_replicas":2 ## 副分片 4
}
}
整个集群中存在P0和P1两个主分片, P0对应的两个R0副本分片, P1对应的是两个R1副本分片。
2.2.3 新建索引处理流程

- 写入的请求会进入主节点, 如果是NODE2副本接收到写请求, 会将它转发至主节点。
- 主节点接收到请求后, 根据documentId做取模运算(外部没有传递documentId,则会采用内部自增ID), 如果取模结果为P0,则会将写请求转发至NODE3处理。
- NODE3节点写请求处理完成之后, 采用异步方式, 将数据同步至NODE1和NODE2节点。
2.2.4 读取索引处理流程

- 读取的请求进入MASTER节点, 会根据取模结果, 将请求转发至不同的节点。
- 如果取模结果为R0,内部还会有负载均衡处理机制,如果上一次的读取请求是在NODE1的R0, 那么当前请求会转发至NODE2的R0, 保障每个节点都能够均衡的处理请求数据。
- 读取的请求如果是直接落至副本节点, 副本节点会做判断, 若有数据则返回,没有的话会转发至其他节点处理。
2.3 ElasticSearch集群部署规划
准备一台虚拟机:
192.168.116.140: Node-1 (节点一), 端口:9200, 9300
192.168.116.140: Node-2 (节点二),端口:9201, 9301
192.168.116.140: Node-3 (节点三),端口:9202, 9302
2.4 ElasticSearch集群配置
解压安装包:
代码语言:javascript复制mkdir /usr/local/cluster
cd /usr/local/cluster
tar -xvf elasticsearch-7.10.2-linux-x86_64.tar.gz将安装包解压至/usr/local/cluster目录。
修改集群配置文件:
代码语言:javascript复制vi /usr/local/cluster/elasticsearch-7.10.2-node1/config/elasticsearch.yml 192.168.116.140, 第一台节点配置内容:
代码语言:javascript复制# 集群名称
cluster.name: my-application
#节点名称
node.name: node-1
# 绑定IP地址
network.host: 192.168.116.140
# 指定服务访问端口
http.port: 9200
# 指定API端户端调用端口
transport.tcp.port: 9300
#集群通讯地址
discovery.seed_hosts: ["192.168.116.140:9300", "192.168.116.140:9301","192.168.116.140:9302"]
#集群初始化能够参选的节点信息
cluster.initial_master_nodes: ["192.168.116.140:9300", "192.168.116.140:9301","192.168.116.140:9302"]
#开启跨域访问支持,默认为false
http.cors.enabled: true
##跨域访问允许的域名, 允许所有域名
http.cors.allow-origin: "*"修改目录权限:
代码语言:javascript复制chown -R elsearch:elsearch /usr/local/cluster/elasticsearch-7.10.2-node1复制ElasticSearch安装目录:
复制其余两个节点:
代码语言:javascript复制cd /usr/local/cluster
cp -r elasticsearch-7.10.2-node1 elasticsearch-7.10.2-node2
cp -r elasticsearch-7.10.2-node1 elasticsearch-7.10.2-node3修改其余节点的配置:
192.168.116.140 第二台节点配置内容:
代码语言:javascript复制# 集群名称
cluster.name: my-application
#节点名称
node.name: node-2
# 绑定IP地址
network.host: 192.168.116.140
# 指定服务访问端口
http.port: 9201
# 指定API端户端调用端口
transport.tcp.port: 9301
#集群通讯地址
discovery.seed_hosts: ["192.168.116.140:9300", "192.168.116.140:9301","192.168.116.140:9302"]
#集群初始化能够参选的节点信息
cluster.initial_master_nodes: ["192.168.116.140:9300", "192.168.116.140:9301","192.168.116.140:9302"]
#开启跨域访问支持,默认为false
http.cors.enabled: true
##跨域访问允许的域名, 允许所有域名
http.cors.allow-origin: "*"192.168.116.140 第三台节点配置内容:
代码语言:javascript复制# 集群名称
cluster.name: my-application
#节点名称
node.name: node-3
# 绑定IP地址
network.host: 192.168.116.140
# 指定服务访问端口
http.port: 9202
# 指定API端户端调用端口
transport.tcp.port: 9302
#集群通讯地址
discovery.seed_hosts: ["192.168.116.140:9300", "192.168.116.140:9301","192.168.116.140:9302"]
#集群初始化能够参选的节点信息
cluster.initial_master_nodes: ["192.168.116.140:9300", "192.168.116.140:9301","192.168.116.140:9302"]
#开启跨域访问支持,默认为false
http.cors.enabled: true
##跨域访问允许的域名, 允许所有域名
http.cors.allow-origin: "*"启动集群节点
先切换elsearch用户, 在三台节点依次启动服务:
代码语言:javascript复制su elsearch
/usr/local/cluster/elasticsearch-7.10.2-node1/bin/elasticsearch -d
/usr/local/cluster/elasticsearch-7.10.2-node2/bin/elasticsearch -d
/usr/local/cluster/elasticsearch-7.10.2-node3/bin/elasticsearch -d注意: 如果启动出现错误, 将各节点的data目录清空, 再重启服务。
集群状态查看
集群安装与启动成功之后, 执行请求: http://192.168.116.140:9200/_cat/nodes?pretty
可以看到三个节点信息,三个节点会自行选举出主节点:

2.5 ElasticSearch集群分片测试
修改kibana的配置文件,指向创建的集群节点:
代码语言:javascript复制elasticsearch.hosts: ["http://192.168.116.140:9200","http://192.168.116.140:9201","http://192.168.116.140:9202"]重启kibana服务, 进入控制台:
http://192.168.116.140:5601/app/home#/
再次创建索引(副本数量范围内):
代码语言:javascript复制PUT orders
{
"settings": {
"index": {
"number_of_shards": 2,
"number_of_replicas": 2
}
}
}可以看到, 这次结果是正常:

集群并非可以随意增加副本数量, 创建索引(超出副本数量范围):
代码语言:javascript复制PUT orders
{
"settings": {
"index": {
"number_of_shards": 2,
"number_of_replicas": 5
}
}
}可以看到出现了yellow警告错误:

好了,至此ES集群搭建完毕,欢迎志同道合的小伙伴,一起交流学习成长。进阶架构师,Fighting!!!
专注Java技术干货分享,欢迎志同道合的小伙伴,一起交流学习
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
发布者:全栈程序员栈长,转载请注明出处:https://javaforall.cn/182381.html原文链接:https://javaforall.cn

