
在python中,用pandas处理数据非常方便。特别是当数据里有异常值的时候,pandas异常值处理的方式就是将NaN的数据转化为None,那么pandas怎么将NaN转化为None呢?接下来的这篇文章带你了解。
但是有时候从其他地方读取数据时,会有异常值需要处理。
比如,我们要从excel读取数据然后调用接口写入数据库时,读取到的空值是NaN,但是,接口接收的对应单元格数据应该是None,这时候怎么处理呢?当然,用pandas做这个事也是非常容易的。
示例如下:
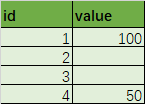
原始数据:
示例代码:
import pandas as pd
df = pd.read_excel('data/test_data.xlsx')
# 将非空数据保留,空数据用None替换
df = df.where(df.notnull(), None)
print(df)
输出结果:
id value
0 1 100
1 2 None
2 3 None
3 4 50
补充:Pandas Nan & None 处理
在处理数据的时候遇到这个问题。
数据库里的值 是null
然后读取数据库后得到的dataframe 里显示的事None.
想把这些None 装换成0.0 但是试过很多方法都不奏效。
使用过
df['PLANDAY'].replace('None',0)
未奏效
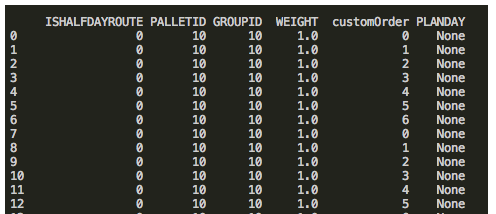
这个判断句是生效的
df.loc[0,'PLANDAY'] is None:
后来发现这个数据类型是Nan 不是None
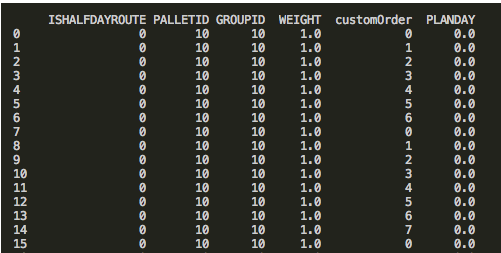
因此使用解决了上诉问题。
df['PLANDAY'] = df['PLANDAY'].fillna(0.0)
以上就是pandas怎么将NaN转换为None的全部内容,希望能给大家一个参考,也希望大家多多支持W3Cschool。

