
近年来,循环神经网络 (RNN) 受到了广泛关注,因为它在许多自然语言处理任务中显示出了巨大的前景。 尽管它们很受欢迎,但解释如何使用最先进的工具实现简单而有趣的应用程序的教程数量有限。在本系列中,我们将使用循环神经网络来训练 AI 程序员,该程序员可以像真正的程序员一样编写 Java 代码(希望如此)。将涵盖以下内容:
2. 改进 AI 程序员 - 使用令牌(这篇文章)
在上一篇文章中,我们使用简单的 1 层 LSTM 神经网络构建了一个基本的 AI 程序员。AI 程序员生成的代码没有多大意义。在这篇文章中,我们将使用标记而不是单个字符序列来训练模型。
1. 获取训练原始数据
我使用与上一篇文章相同的源代码。它可以在这里找到:https://github.com/frohoff/jdk8u-jdk。这一次,每个 .java 文件都被扫描、标记化,然后聚合到一个名为“jdk-tokens.txt”的文件中。不保留换行符。你不需要下载 JDK 源代码。为方便起见,我已将聚合文件包含在该项目的 GitHub 存储库中。你可以在这篇文章的末尾找到链接。
以下代码从 jdk-tokens.txt 文件中读取令牌并将其切片以适合我的桌面的硬件功能。就我而言,我只使用了代码中显示的代码的 20%。
path = "./jdk-tokens.txt"
filetext = open(path).read().lower()
# slice the whole string to overcome memory limitation
slice = len(filetext)/5
slice = int (slice)
filetext = filetext[:slice]
tokenized = filetext.split()
print('# of tokens:', len(tokenized))2. 建立索引来定位令牌
LSTM 输入只理解数字。将标记转换为数字的一种方法是为每个标记分配一个唯一的整数。例如,如果代码中有 1000 个唯一令牌,我们可以为 1000 个令牌中的每一个分配一个唯一编号。下面的代码构建了一个包含 [“public” : 0 ] [ “static” : 1 ], ... ] 等条目的字典。还生成反向字典用于解码 LSTM 的输出。
uniqueTokens = sorted(list(set(tokenized)))
print('total # of unique tokens:', len(uniqueTokens))
token_indices = dict((c, i) for i, c in enumerate(uniqueTokens))
indices_token = dict((i, c) for i, c in enumerate(uniqueTokens))3. 准备带标签的训练序列
在这里,我们以 10 个标记的半冗余序列剪切文本。每个序列是一个训练样本,每个令牌序列的标签是下一个令牌。
NUM_INPUT_TOKENS = 10
step = 3
sequences = []
next_token = []
for i in range(0, len(tokenized) - NUM_INPUT_TOKENS, step):
sequences.append(tokenized[i: i + NUM_INPUT_TOKENS])
next_token.append(tokenized[i + NUM_INPUT_TOKENS])
print('nb sequences:', len(sequences))4. 向量化训练数据
我们首先创建两个矩阵,然后为每个矩阵赋值。一种用于特征,一种用于标签。len(sequences) 是训练样本的总数。
X = np.zeros((len(sequences), NUM_INPUT_TOKENS, len(uniqueTokens)), \
dtype=np.bool)
y = np.zeros((len(sequences), len(uniqueTokens)), dtype=np.bool)
for i, sentence in enumerate(sequences):
for t, char in enumerate(sentence):
X[i, t, token_indices[char]] = 1
y[i, token_indices[next_token[i]]] = 15. 构建单层 LSTM 模型
我们正在构建一个如下所示的网络:
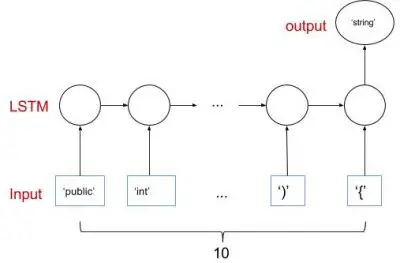
此外,堆叠两个 LSTM 层非常简单,如下面的注释代码所示。
下面的代码定义了神经网络的结构。该网络包含一层具有 128 个隐藏单元的 LSTM。input_shape 参数指定输入序列的长度和每次输入的维度。Dense() 实现output = activation(dot(input, kernel) + bias)。这里的输入是 LSTM 层的输出。激活函数由行 Activation('softmax') 指定。Optimizer 是优化函数。您可能熟悉逻辑回归中常用的一种,即随机梯度下降。最后一行指定了成本函数。在这种情况下,我们使用“categorical_crossentropy”。
model = Sequential()
# 1-layer LSTM
#model.add(LSTM(128, input_shape=(NUM_INPUT_TOKENS, len(uniqueTokens))))
# 2-layer LSTM
model.add(LSTM(128,return_sequences=True, \
input_shape=(NUM_INPUT_TOKENS, len(uniqueTokens))))
model.add(LSTM(128))
model.add(Dense(len(uniqueTokens)))
model.add(Activation('softmax'))
optimizer = RMSprop(lr=0.01)
model.compile(loss='categorical_crossentropy', optimizer=optimizer)
print(model.summary())6.训练模型和生成Java代码
上面,我还包含了堆叠另一层 LSTM 并使其成为 2 层 LSTM RNN 的代码。
sample 函数用于从概率数组中采样一个索引。例如,给定 preds=[0.5,0.2,0.3] 和默认温度,函数返回索引 0 的概率为 0.5、1 的概率为 0.2 或 2 的概率为 0.3。它用于避免一遍又一遍地生成相同的句子。我们希望看到 AI 程序员可以编写的一些不同的代码序列。
def sample(preds, temperature=1.0):
# helper function to sample an index from a probability array
preds = np.asarray(preds).astype('float64')
preds = np.log(preds) / temperature
exp_preds = np.exp(preds)
preds = exp_preds / np.sum(exp_preds)
probas = np.random.multinomial(1, preds, 1)
return np.argmax(probas)
# train the model, output generated code after each iteration
for iteration in range(1, 60):
print()
print('-' * 50)
print('Iteration', iteration)
model.fit(X, y, batch_size=128, epochs=1)
start_index = random.randint(0, len(tokenized) - NUM_INPUT_TOKENS - 1)
for diversity in [0.2, 0.5, 1.0, 1.2]:
print()
print('----- diversity:', diversity)
generated = [] #''
sequence = tokenized[start_index: start_index + NUM_INPUT_TOKENS]
generated=list(sequence)
print('----- Generating with seed: "' + ' '.join(sequence) + '"-------')
sys.stdout.write(' '.join(generated))
for i in range(100):
x = np.zeros((1, NUM_INPUT_TOKENS, len(uniqueTokens)))
for t, char in enumerate(sequence):
x[0, t, token_indices[char]] = 1.
preds = model.predict(x, verbose=0)[0]
next_index = sample(preds, diversity)
next_pred_token = indices_token[next_index]
generated.append(next_pred_token)
sequence = sequence[1:]
sequence.append(next_pred_token)
sys.stdout.write(next_pred_token+" ")
sys.stdout.flush()
print()7. 结果
训练模型需要几个小时。我在第 40 次迭代时停止,生成的代码如下所示:
----- Generating with seed: "true ) ; } else { boolean result = definesequals"-------
true ) ; } else { boolean result = definesequals
( ) . substring ( 1 , gradients . get ( p ) ; }
if ( val . null || ( npoints == null ) ? new void . bitlength ( ) + prefixlength ) ;
for ( int i = 0 ; i < num ; i ++ ) } break ; }
if ( radix result = != other . off ) ;
int endoff = b . append ( buf , 0 , len + 1 ) ; digits ++ ] ; 代码生成看起来比以前基于字符的方法生成的代码要好得多。请注意,为了便于阅读,我添加了换行符。我们可以看到 LSTM 很好地捕获了循环和条件,代码开始变得更有意义。例如,“for ( int i = 0 ; i < num ; i ++ )” 是一个完美的 Java for循环。如果调整参数(如 NUM_INPUT_CHARS 和 STEP)并训练更长时间,可能会得到更好的结果。随意尝试。同样,我已经知道完成这项工作的更好方法,所以我停在这里并在下一篇文章中进行改进。
你还可以查看早期迭代中生成的代码。他们的意义不大。
8. 下一步是什么?
在这篇文章中,我使用令牌序列作为输入来训练模型,模型预测令牌序列。如果一切正常,它应该比基于字符的方法更有效。此外,我们还可以使用不同的网络结构。我们将在下一篇文章中探讨这些。

