
近年来,循环神经网络 (RNN) 受到了广泛关注,因为它在许多自然语言处理任务中显示出了巨大的前景。 尽管它们很受欢迎,但解释如何使用最先进的工具实现简单而有趣的应用程序的教程数量有限。在本系列中,我们将使用循环神经网络来训练 AI 程序员,该程序员可以像真正的程序员一样编写 Java 代码(希望如此)。将涵盖以下内容:
3. 改进 AI 程序员 - 使用不同的网络结构(这篇文章)
在之前的文章中,我们分别使用字符和标记作为训练数据构建了一个基本的 AI 程序员。这两种方法都使用一个简单的 1 层 LSTM 神经网络。更具体地说,网络使用多对一的结构,如下图所示:
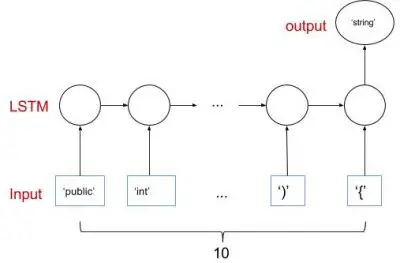
对于序列到序列的预测,还有其他结构,例如一对多和多对多。在这篇文章中,我们将实现一个简单的多对多网络结构,如下所示。代码被推送到 GitHub 上的同一个存储库(本文末尾提供了链接)。
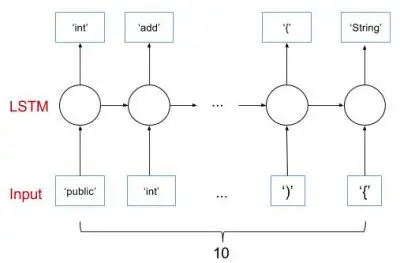
由于代码的大部分与上一篇文章相同,我在这里只强调不同之处。
1.准备训练数据
由于这次我们将预测一个序列而不是下一个标记,因此 y 也应该是一个序列。y 是从 X 左移 1 的序列。
NUM_INPUT_TOKENS = 10
step = 3
sequences = []
for i in range(0, len(tokenized) - NUM_INPUT_TOKENS-1, step):
sequences.append(tokenized[i: i + NUM_INPUT_TOKENS+1])
print('# of training sequences:', len(sequences))
X_temp = np.zeros((len(sequences), NUM_INPUT_TOKENS + 1, len(uniqueTokens)), dtype=np.bool)
X = np.zeros((len(sequences), NUM_INPUT_TOKENS, len(uniqueTokens)), dtype=np.bool)
y = np.zeros((len(sequences), NUM_INPUT_TOKENS, len(uniqueTokens)), dtype=np.bool)
for i, sequence in enumerate(sequences):
for t, char in enumerate(sequence):
X_temp[i, t, token_indices[char]] = 1
num_sequences = len(X_temp)
for i, vec in enumerate(X_temp):
y[i] = vec[1:]
X[i]= vec[:-1]2. 构建多对多循环神经网络
这是构建多对多循环网络的代码。
model = Sequential()
model.add(LSTM(128, input_shape=(NUM_INPUT_TOKENS, len(uniqueTokens)), return_sequences=True))
model.add(TimeDistributed(Dense(len(uniqueTokens))))
model.add(Activation('softmax'))
optimizer = RMSprop(lr=0.01)
model.compile(loss='categorical_crossentropy', optimizer=optimizer)
print(model.summary())你可以打印网络结构:
_________________________________________________________________ Layer (type) Output Shape Param # ================================================================= lstm_1 (LSTM) (None, 10, 128) 670208 _________________________________________________________________ time_distributed_1 (TimeDist (None, 10, 1180) 152220 _________________________________________________________________ activation_1 (Activation) (None, 10, 1180) 0 =================================================================
就像我们为多对一结构所做的那样,我们也可以轻松地多堆叠一层 LSTM,如下所示:
model = Sequential()
model.add(LSTM(128, return_sequences=True, input_shape=(NUM_INPUT_TOKENS, len(uniqueTokens))))
model.add(LSTM(128, return_sequences=True))
model.add(TimeDistributed(Dense(len(uniqueTokens))))
model.add(Activation('softmax'))
optimizer = RMSprop(lr=0.01)
model.compile(loss='categorical_crossentropy', optimizer=optimizer)
print(model.summary())网络结构是这样的:
_________________________________________________________________ Layer (type) Output Shape Param # ================================================================= lstm_1 (LSTM) (None, 10, 128) 670208 _________________________________________________________________ lstm_2 (LSTM) (None, 10, 128) 131584 _________________________________________________________________ time_distributed_1 (TimeDist (None, 10, 1180) 152220 _________________________________________________________________ activation_1 (Activation) (None, 10, 1180) 0 =================================================================
3. 结果
经过几次迭代,结果看起来比之前的多对一网络要好。我强烈建议你在运行代码能够有自己的观察并思考原因。那将是一个很好的练习。
runattributes = numberelements [ i ] . offsets [ currindex ] ;
patternentry ucompactintarray ;
import sun . util . oldstart ; 4. 下一步是什么?
在这篇文章中,我使用了多对多结构的网络来训练模型,模型预测令牌序列。也许为了好玩,你也可以尝试一对多网络。此外,我们还可以调整许多其他参数,以加快训练速度并使 AI Programmer 变得更好。

